
1.8. Normal distribution#
In this section we simulate some data from a normal distribution
1.8.1. Heights example#
Let’s simulate a dataset with the heights of 10,000 men and 10,000 women, based on our knowledge that
- height is normally distributed
- we know the mean and sd of mens' and womens' heights in the UK
Set up Python libraries#
As usual, run the code cell below to import the relevant Python libraries
# Set-up Python libraries - you need to run this but you don't need to change it
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas
import seaborn as sns
sns.set_theme() # use pretty defaults
Create the simulated dataset#
We use the function np.random
men = np.random.normal(175,7, [10000])
women = np.random.normal(162,7, [10000])
sns.histplot(men, color='b', label='men')
sns.histplot(women, color='r', label='women')
plt.legend()
plt.show()
/opt/anaconda3/anaconda3/lib/python3.11/site-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
/opt/anaconda3/anaconda3/lib/python3.11/site-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
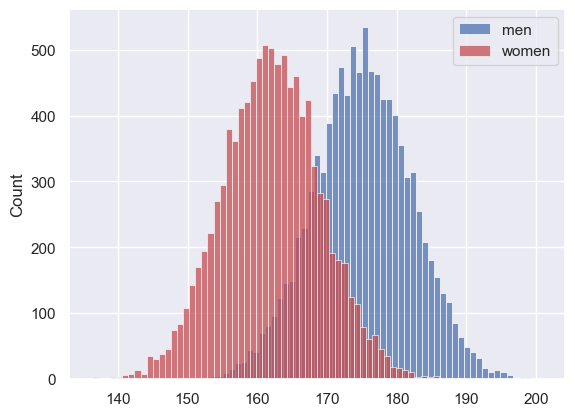
- Where in the code do we specify the mean of the desired distribution?
- Where in the code do we specify the sd of the desired distribution?
- Where in the code do we specify the sample size to be simulated?
The PDF and CMF#
We can plot the theoretical distriubtion or Probabbility Density Function of the normal distribution using scipy.stats.
This is similar to plotting the PMF of the binomial:
x = range(140,190,1)
p_x = stats.norm.pdf(x,162,7)
freq = p_x*10000 #(get expected frequencies by multiplying by n)
sns.histplot(women, bins=range(140,190,1), color='r', label='women')
plt.plot(x, freq, 'k.-')
plt.show()
/opt/anaconda3/anaconda3/lib/python3.11/site-packages/seaborn/_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
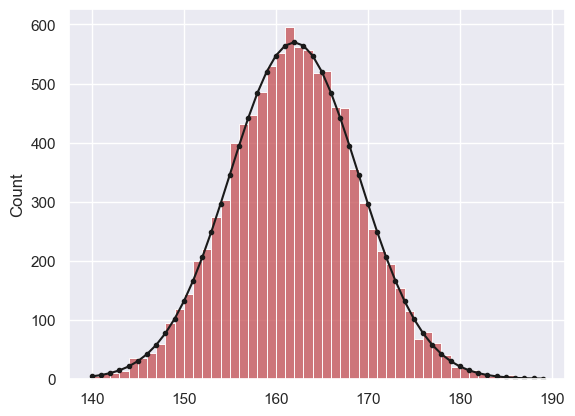
If we want to know what proportion of women are over 180cm (6’) tall, we can work it out using the CDF - the proportion greater than 1800cm tall is 1-CDF(180)
1 - stats.norm.cdf(180,162,7)
0.005063995274695365
… about half of one percent, or one in two hundred women are over 180cm/6’ tall.
- Can you check what proportion of simulated women were over 180cm tall?
- Does it match the value from the theoretical CDF quite well?
Parameters of the normal distrubition#
All normally distributed variables have the same shape of distribution (the bell curve), but two parameters determine the location and spread of the distribution -
the mean \(\mu\) determines the location of the curve along the x axis
the standard deviation \(\sigma\) determines the spread or width of the curve
We sometimes describe a normal distribution using the following notation:
pronounced “\(x\) follows a Normal with mean \(\mu\) and standard deviation \(\sigma\)
for example
… describes the distribution of womens’ heights used above
Let’s plot some examples:
x = range(101)
plt.plot(x,stats.norm.pdf(x,30,7) )
plt.plot(x,stats.norm.pdf(x,30,15))
plt.plot(x,stats.norm.pdf(x,60,7) )
plt.xlabel('$x$')
plt.ylabel('$p(x)$')
plt.show()
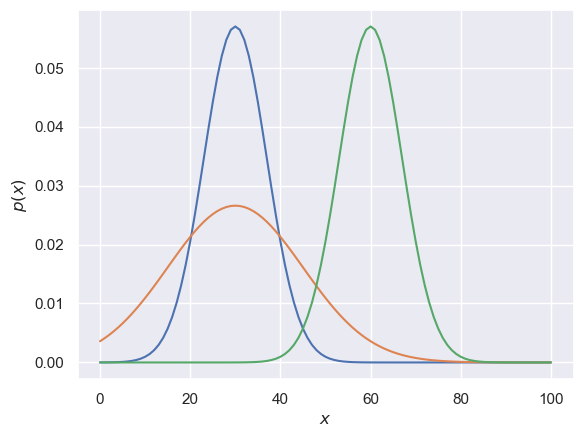
The code above plots three normal distributions.
- what are the means and standard deviations of the distributions?
- which line of code plots which?
- add a line of code to add a normal N(50,5)
1.8.2. Z-score#
For normally distributed variables, we sometimes refer to the Z-score of a value.
The Z-score tells us how many standard deviations above or below the mean of the distribution a given value lies.
For example, for women’s heights the standard deviation \(\sigma\) is 7 and the mean is 162cm, so a woman 169cm tall (one sd above the mean) has a Z-score of 1
A woman whose height is \(2\sigma\) below the mean (148cm) has a Z-score of -2.
- What is the Z-score of a woman whose height is 172.5cm?
- What about a woman whose height is 150cm?
Reporting the Z-score of a value is useful as we automatically know where the value sits on the normal curve without having to check the normal CDF on Python or in a table (because the probability of obtaining a given Z-score does not depend on the mean and sd of the given dataset)
For example, a Z-score greater than 1.65 occurs only 5% of the time and a Z score greater than 2.6 occurs only 1% of the time.