
2.4. Visualizing Distributions#
sns.histplot()sns.kdeplot()
If we want to see the shape of a data distribution, the histogram can be a good choice. From a histogram we can easily see if a data distribution:
is unimodal or multimodel
has skew, or is symmetrical
differs between two samples
In this section we will see how to plot a histogram using Python and what choices we can make to show the data distribution clearly and accurately
Here is a video about the use of histograms
%%HTML
<iframe width="560" height="315" src="https://www.youtube.com/embed/duALLohtvms?si=-om7mGr3-2G9yOWu" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe>
We will also consider some of the limitations of the histogram for small datasets, and explore a related plot, the Kernel Density Estimate (KDE) plot, which can mitigate these limitations.
To summarize the conceptual content of this page, when plotting a histogram we should consider:
the width of the bins - narrow bins give more detail but may make it harder to perceive the overall pattern
the KDE-plot equivalent is bandwidth which determines the smoothness of the KDE shape
the bin boundaries - do we want to place them at round numbers or some other meaningful point?
When using histograms (and KDE plots) to compare distributions, we should consider:
matching the scale on the axes to facilitate comparison
whether to place the two plots next to each other (horizontally), above one another (vertically) or overlaid (on the same axis), to facilitate comparison
Here is a video about KDE plots
%%HTML
UsageError: %%HTML is a cell magic, but the cell body is empty.
2.4.1. Example#
We will look at a small sample of height data (these are made-up data designed for the exercise).

Set up Python libraries#
As usual, run the code cell below to import the relevant Python libraries
# Set-up Python libraries - you need to run this but you don't need to change it
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas as pd
import seaborn as sns
sns.set_theme(style='white')
import statsmodels.api as sm
import statsmodels.formula.api as smf
import warnings
warnings.simplefilter('ignore', category=FutureWarning)
Load and inspect the data#
Load the file BodyData.csv which contains body measurements for 50 (fictional) people. The code block below will load the data automatically from the internet.
heightData = pd.read_csv('https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook_2024/main/data/BodyData.csv')
display(heightData)
| ID | sex | height | weight | age | |
|---|---|---|---|---|---|
| 0 | 101708 | M | 161 | 64.8 | 35 |
| 1 | 101946 | F | 165 | 68.1 | 42 |
| 2 | 108449 | F | 175 | 76.6 | 31 |
| 3 | 108796 | M | 180 | 81.0 | 31 |
| 4 | 113449 | F | 179 | 80.1 | 31 |
| 5 | 114688 | M | 172 | 74.0 | 42 |
| 6 | 119187 | F | 148 | 54.8 | 45 |
| 7 | 120679 | F | 160 | 64.0 | 44 |
| 8 | 120735 | F | 188 | 88.4 | 32 |
| 9 | 124269 | F | 172 | 74.0 | 29 |
| 10 | 124713 | M | 175 | 76.6 | 26 |
| 11 | 127076 | M | 180 | 81.0 | 28 |
| 12 | 131626 | M | 162 | 65.6 | 35 |
| 13 | 132218 | M | 170 | 72.3 | 29 |
| 14 | 132609 | F | 172 | 74.0 | 41 |
| 15 | 134660 | F | 159 | 63.2 | 34 |
| 16 | 135195 | M | 169 | 71.4 | 42 |
| 17 | 140073 | F | 168 | 70.6 | 34 |
| 18 | 140114 | M | 195 | 95.1 | 41 |
| 19 | 145185 | F | 157 | 61.6 | 45 |
| 20 | 146279 | F | 180 | 81.0 | 30 |
| 21 | 146519 | F | 172 | 74.0 | 34 |
| 22 | 151451 | F | 171 | 73.1 | 37 |
| 23 | 152597 | M | 172 | 74.0 | 27 |
| 24 | 154672 | M | 167 | 69.7 | 39 |
| 25 | 155594 | F | 165 | 68.1 | 25 |
| 26 | 158165 | M | 175 | 76.6 | 45 |
| 27 | 159457 | F | 176 | 77.4 | 36 |
| 28 | 162323 | M | 173 | 74.8 | 31 |
| 29 | 166948 | M | 174 | 75.7 | 28 |
| 30 | 168411 | M | 175 | 76.6 | 29 |
| 31 | 168574 | F | 163 | 66.4 | 30 |
| 32 | 169209 | F | 159 | 63.2 | 45 |
| 33 | 171236 | F | 164 | 67.2 | 34 |
| 34 | 172289 | M | 181 | 81.9 | 27 |
| 35 | 173925 | M | 189 | 89.3 | 25 |
| 36 | 176598 | F | 169 | 71.4 | 37 |
| 37 | 177002 | F | 180 | 81.0 | 36 |
| 38 | 178659 | M | 181 | 81.9 | 26 |
| 39 | 180992 | F | 177 | 78.3 | 31 |
| 40 | 183304 | F | 176 | 77.4 | 30 |
| 41 | 184706 | M | 183 | 83.7 | 40 |
| 42 | 185138 | M | 169 | 71.4 | 28 |
| 43 | 185223 | F | 170 | 72.3 | 41 |
| 44 | 186041 | M | 175 | 76.6 | 25 |
| 45 | 186887 | M | 154 | 59.3 | 26 |
| 46 | 187016 | M | 161 | 64.8 | 32 |
| 47 | 198157 | M | 180 | 81.0 | 33 |
| 48 | 199112 | M | 172 | 74.0 | 33 |
| 49 | 199614 | F | 164 | 67.2 | 31 |
2.4.2. Histogram#
Let’s start by plotting a histogram of the data to see what the distribution of heights is.
We use the Seaborn function sns.histplot()
sns.histplot(data = heightData, x="height")
plt.xlabel('height') # set the x axis label
plt.show() # this command asks Python to output the plot created above
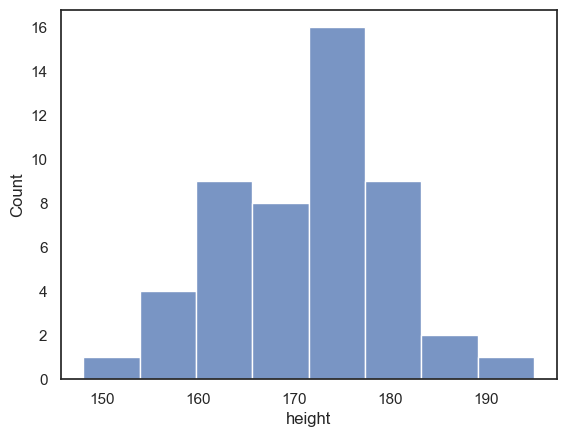
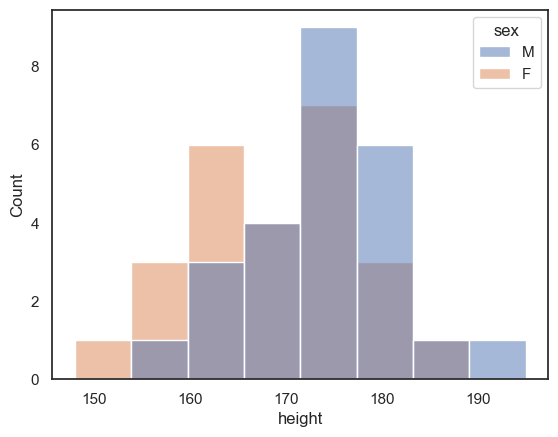
If we want to disaggregate (separate out) the data, for example by sex, this is super easy using the hue property in Seaborn functions:
sns.histplot(data = heightData, x="height", hue="sex")
plt.xlabel('height') # set the x axis label
plt.show() # this command asks Python to output the plot created above
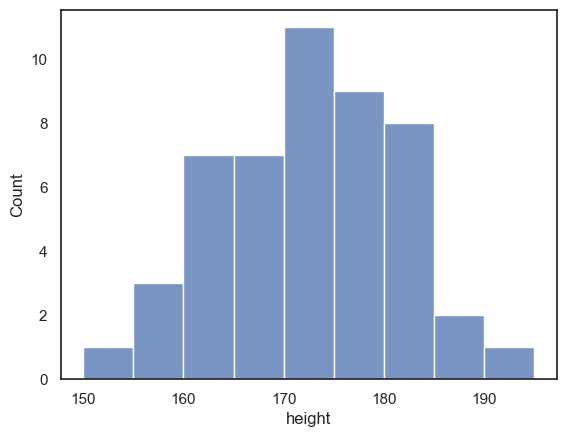
Choosing the bin boundaries and width#
In a histogram, we group data into bins, and count how many data values fall in each bin
By default, Seaborn chooses a set of bins that its algorithm suggests should best display the shape of the data distribution.
However, we may prefer to set the bin widths to values that are more easily interpretable.
For example, below I used bins of 5cm to group the heights (in a range from 150 to 200 cm that includes all the data points in my sample). This means I can easily read off from the graph how many men in my sample have a height between, say, 170 and 175cm).
Can you find where in the code this is specified?
sns.histplot(data = heightData, x="height", bins = range(150,200,5))
plt.show() # this command asks Python to output the plot created above
Histogram is unstable for small \(n\)#
One problem with using a histogram when you have only a small number of data points is that the shape of the histogram can depend a lot on where the bin boundaries happen to fall.
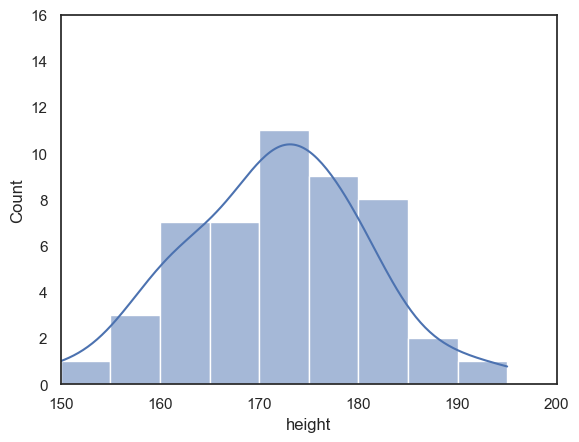
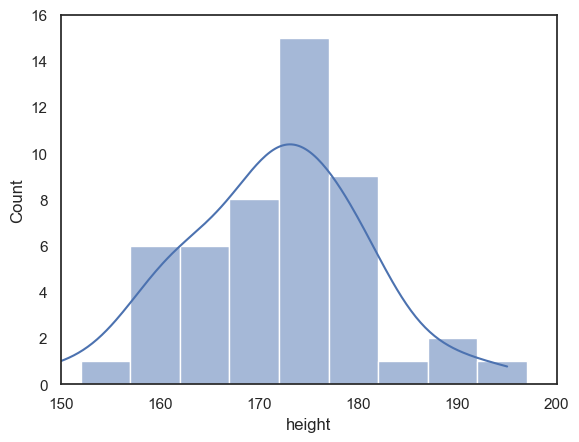
Look at the following plot of brothers’ heights, again grouped into 5cm bins but with different bin boundaries:
sns.histplot(data = heightData, x="height", bins = range(152,202,5))
plt.show()
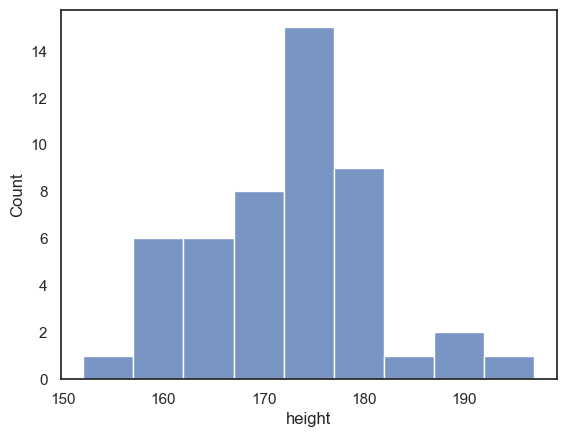
Compare the histogram to the one above with bin boundaries at 150, 155 etc. The shape of the distribution looks quite different! In the top plot, we seem to have quite a broad distribution, whereas in the bottom one, there is a big spike of people with heights betweem 172 and 177 cm.
Moving the bin boundaries changed how many observations fell in each bin and thus the shape of the histogram. This can happen easily just due to chance when you have a small number of observations in each bin (check the y-axis in the above histogram - you can see that most bins contain fewer than 10 people, which means that moving just one or two observations between bins makes a big difference to the apparent shape of the histogram).
For this reason, a histogram may not be the best representation of the data for a small sample.
Exercises#
What change in the code moved the bin boundaries?
What were the old bin boundaries? What are the new bin boundaries?
Create a new histogram in which the bin boundaries are at 153,158,163 etc
# your code here!
Bin width#
The code above creates histograms of the people’s heights. You can copy and paste it, then modify it, to complete the following exercise:
create a histogram with bin widths of 1cm - can you guess how to do this?
note how much spikier the histogram looks with 1cm bins - it is hard to see the overall shape of the distribution
# your code here!
2.4.3. KDE plot#
Whist a histogram shows the number of observations in each of a set of discrete bins, the KDE plot estimates a smooth distribution shape that fits the underlying observations.
You can think of it as the average of all the histograms you would get if you tried all the possible sets of bin boundaries (for a fixed bin width).
We can add a kde plot to the histogram by adding an extra argument to the function sns.histplot. Here we reproduce the two different histograms of brothers’ heights with different bin boundaries, with the KDE plot added.
although the histograms look rather different, the KDE plots look exactly the same as each other
note-
I used some additional commands from
Matplotlibto make sure the x and y axes cover the same range of values for both plots, to make them easier to compare
sns.histplot(data = heightData, x="height", bins = range(150,200,5), kde="True")
plt.xlim(150,200)
plt.ylim(0,16)
plt.show()
# note that without the command plt.show(), Jupyter will put all plots onto the same axes,
# or (if that is impossible, eg when different plot types were used)
# display only the final plot created in the cell
sns.histplot(data = heightData, x="height", bins = range(152,202,5), kde="True")
plt.xlim(150,200)
plt.ylim(0,16)
plt.show()
Exercises#
Can you find the extra argument that adds the KDE plot?
Try to switch the KDE plot off!
2.4.4. KDE plot (without histogram)#
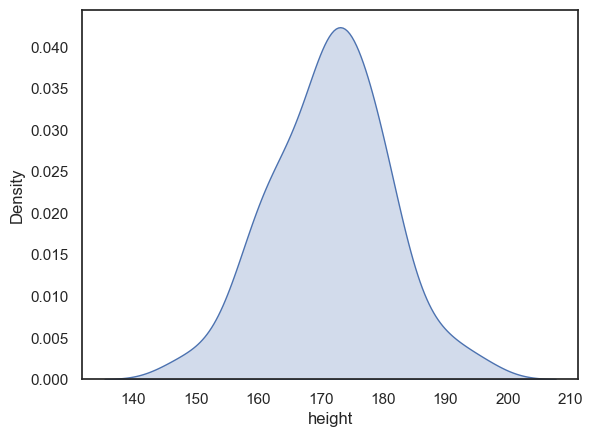
If you don’t want the histogram, you can plot the KDE plot independently (without a histogram), using the Seaborn function sns.kdeplot()
sns.kdeplot(data = heightData, x="height", fill=True) # I think KDE plots look nice filled with shading, hence fill=True
plt.xlabel('height') # set the x axis label
plt.show()
Probability density#
When we plot the KDE as a standalone (rather than over a histogram) the x-axis changes to ‘Density’ rather than ‘count’.
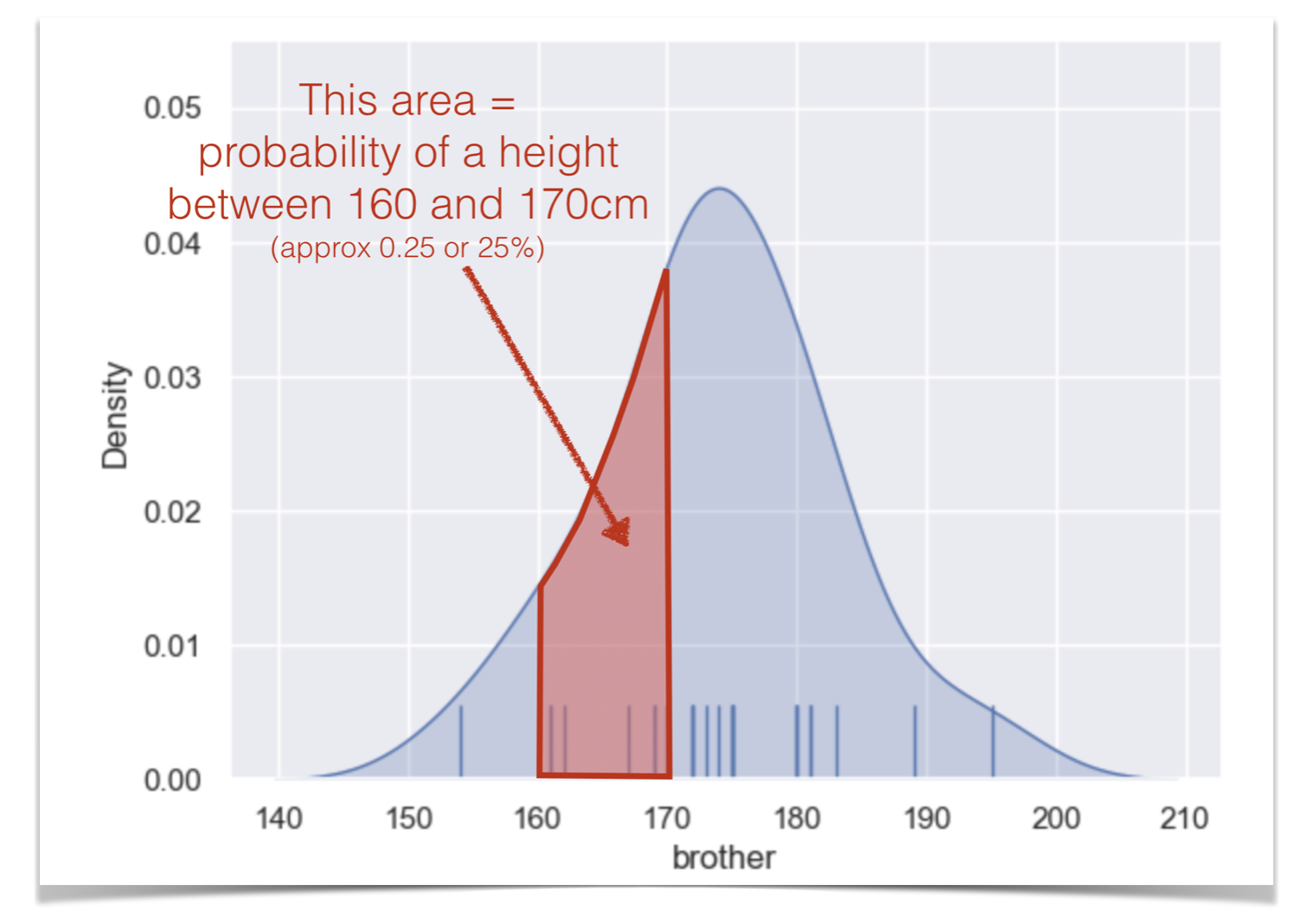
The values of density are such that the area under the curve of the KDE plot is 1. Technically it is a probability density. It means that probabilities could be read off the graph - so the probability of a member of our sample (one of people in the dataframe) having a height between 160 and 170cm is the same as the area under the curve between 160 and 170cm.
• this is calculated as 10cm (width of the shaded area) x 0.025 (average ‘density’ in this area) = 0.25 or 25%
One consequence of this is that you cannot tell from the KDE plot how many data points were in the dataset (which we should care about, as laager datasets are more likely to reliably represent the population!). To counter this you can add a rugplot, which shows the individual datapoints - this gives you ‘the best of both worlds’
sns.kdeplot(data = heightData, x="height", fill=True)
sns.rugplot(data = heightData, x="height")
plt.xlabel('height') # set the x axis label
plt.show()
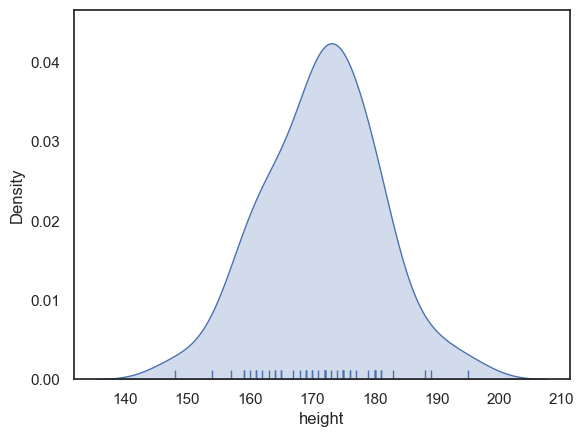
Bandwidth#
I said you can think of the KDE plot as a kind of average of all the histograms you would get if you tried all the possible locations for bin boundaries (150,155,160, vs 151,156,161 etc)
This is true but it only averages histograms for one possible bin width, which is chosen by the computer to give (generally) a good result.
You saw above that changing the bin width from 5cm to 1cm changed the balance between showing to overall shape of the distribution (where is the main peak) vs the details (details more visible with a small bin boundary). Bandwidth does the equivalent adjustment in a KDE plot.
The code below shows the height KDE with three bandwidths. The argument bw_adjust is a scaling factor for the default bandwidth chosen by the computer:
If bw_adjust = 1.0 the default bandwidth is used (grey KDE)
If bw_adjust = 0.5, a narrower bandwith of half the default is used (red KDE)
If bw_adjust = 2.0, a wider bandwith of twice the default is used (blue KDE)
sns.kdeplot(data = heightData, x="height", fill=True, bw_adjust=1.0, color='k')
sns.kdeplot(data = heightData, x="height", fill=True, bw_adjust=0.5, color='r')
sns.kdeplot(data = heightData, x="height", fill=True, bw_adjust=2.0, color='b')
plt.xlabel('height') # set the x axis label
plt.show()
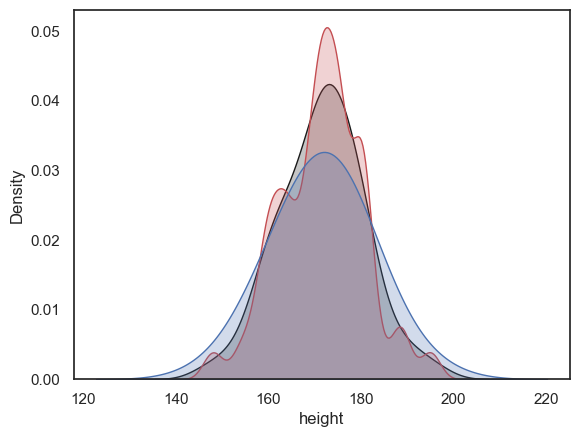
Note With its high bandwidth, the blue KDE plot looks very smooth with just one peak.
In contrast, with low bandwidth, the red KDE plot tracks local peaks in the data distribution, resulting in lots of little bumps in the KDE plot.
Exercise#
Try out some different values for bw_adjust - can you make the KDE plot go even wobblier? or even smoother?
2.4.5. Considerations when comparing distributions#
Histograms and KDE plots are good for showing the shape of a data distribution, and hence they are also good for comparing the shape of multiple data distributions
An easy way to compare two groups is to overlay the histograms or KDE plots, using the hue property:
sns.histplot(data = heightData, x="height", hue='sex', bins = range(150,200,5))
plt.show()
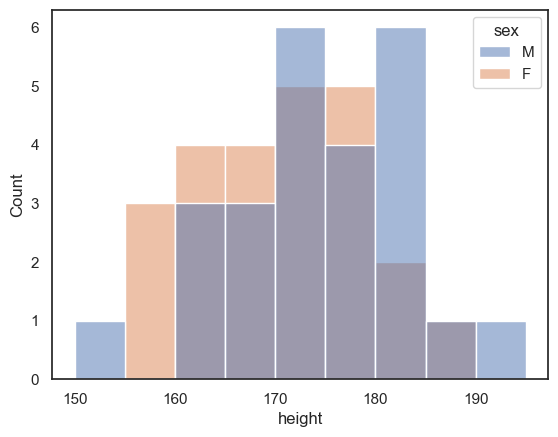
You might find that too crowded in which case you may want to separate out the plots onto two separate axes:
sns.histplot(data = heightData.query('sex=="M"'), x="height", color='b')
plt.show()
sns.histplot(data = heightData.query('sex=="F"'), x="height", color='r')
plt.show()
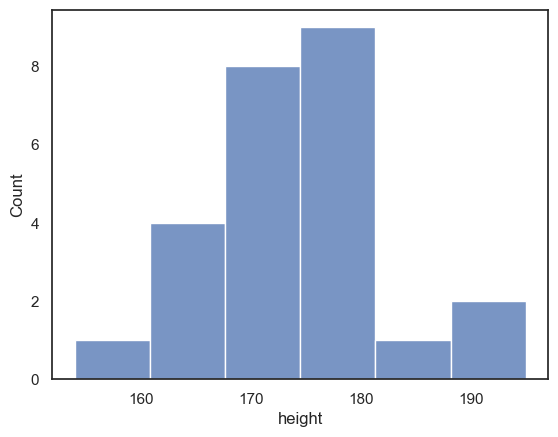
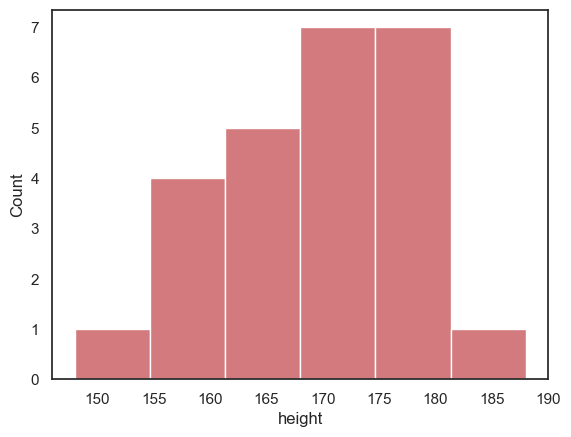
However, when we try to compare the two plots on separate axes, the matter is confused by non-matching axis ranges
It looks like there are more tall women than tall men, because the peak fo the distribution is further right for the women - but check out the numbers on the \(x\)-axes
The most common bin for men contains 9 people, but for women, 7 people - this is not immediately apparent as the \(y\)-axes don’t match
luckily
seaborngrouped both men and women into 6 bins - but the bin widths are not actually the same in the two plots
To make the plots more directly comparable, we should fix the range of \(x\) and \(y\) axes and the bin boundaries on both plots:
sns.histplot(data = heightData.query('sex=="M"'), x="height", color='b', bins=range(150,200,5))
plt.xlim(150,200)
plt.ylim(0,8)
plt.show()
sns.histplot(data = heightData.query('sex=="F"'), x="height", color='r', bins=range(150,200,5))
plt.xlim(150,200)
plt.ylim(0,8)
plt.show()
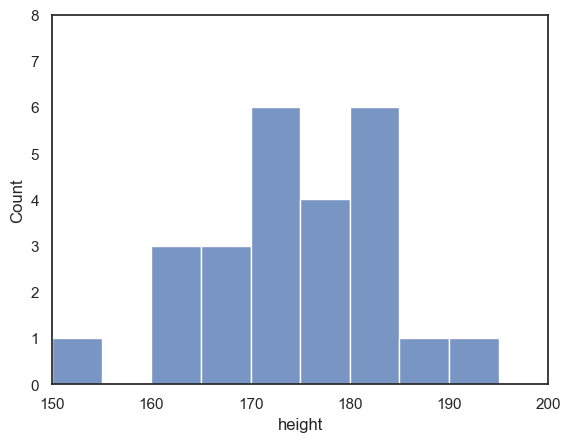
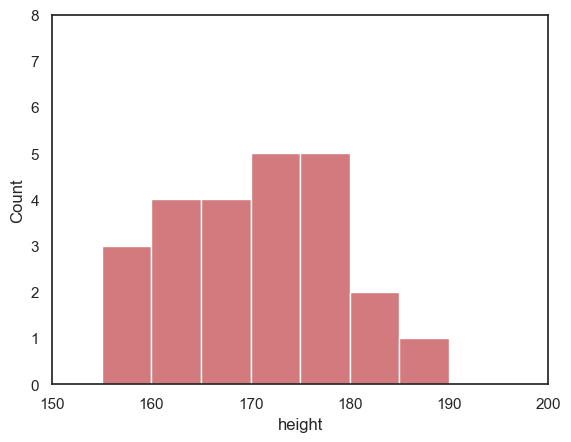
2.4.6. Customizing the appearance of your plots#
I told you that seaborn produces publication quality figures, but some of the figures above look a bit ugly.
We can easily change the appearance of our plots using some additional arguments to the functions sns.histplot() and sns.kdeplot().
You can find many examples of how to change the appearance of histograms and KDE plots in the seaborn manual pages:
for sns.histplot() and sns.kdeplot()