
2.5. Handling different variable types in regression analysis#
So far, we have assumed that the x variables in the regression analysis are continuous. However, we can include different types of x variable in regression analysis.
How can regression handle binary x variables?
Click to reveal answer
A binary variable such as “smoker” could be coded as [0,1] where people who smoke have the value 1 and people who don’t smoke have the value 0. In a regression model of health, for example, the estimated slope for smoker could be -1.45, and we would interpret this as follows: the health of smokers is 1.45 points lower than non-smokers.
What is a “dummy variable”?
Click to reveal answer
A dummy variable is one that the researcher has coded as 0,1 to represent having (or not having) a particular attribute (such as being a smoker, or not).
Handling categorical variables follows the same logic as binary variables (though it gets a little more complicated). Let’s say we would like to treat smoking as a categorical variable with 3 categories: 1) current smoker, 2) ex-smoker, 3) never smoked.
The first 10 data points look like this:
Note that in this example, health is a self-rated measure that runs from 1 (poor health) to 5 (excellent health).
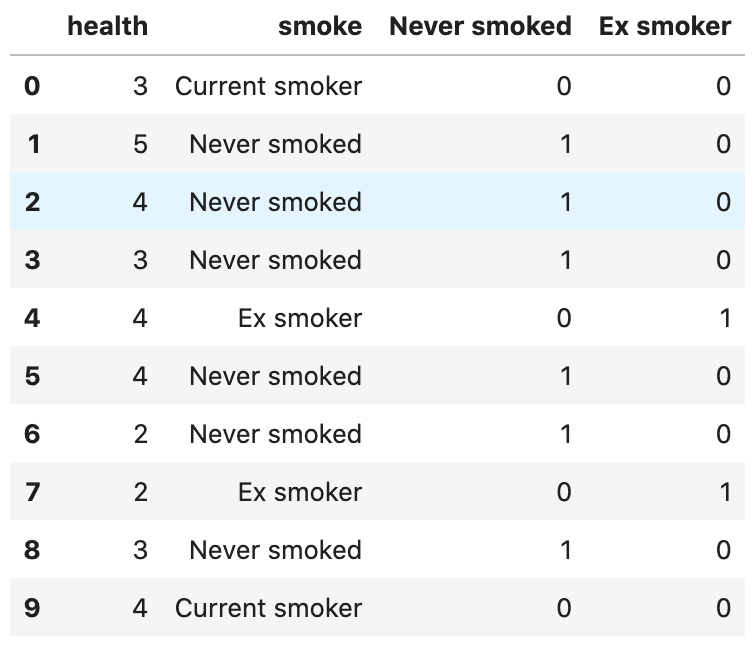
We could manipulate the data in the following way, capturing each category as a “dummy variable”, where the smoking status for each row of data is captured in zeros and ones. An important feature of this approach is that we have all the information we need from TWO dummy variables, not THREE. Indeed, we always need [number of categories – 1] number of dummy variables (this was also the case with the binary example, which is more intuitive but the same logic).
In row 1, the person has a zero for never smoked and a zero for ex-smoker, so they must be a current smoker. The people who have never smoked have a 1 for never smoked, and the ex-smokers have a 1 for ex-smoker. Thus, we get all the information we need without a separate dummy variable for “current smoker” which we will treat, in this example, as the reference category or omitted category (two terms for the same thing).
The Python output for this example looks like this:
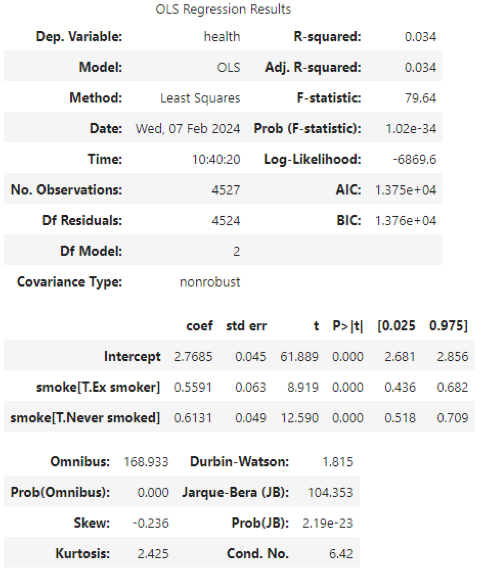
How would you interpret the results about smoking status and health?
Click to reveal answer
To interpret the coefficients, we need to compare them to the omitted category, which is “current smoker”. These results suggest that people who have never smoked have a health of 0.6131 points higher than current smokers, and ex-smokers have health that is 0.5591 points higher than current smokers.
If you wanted to include a categorical variable in your regression analysis that has 6 categories, how many dummy variables would you expect to see in the model output?
Click to reveal answer
5
Do I need to create my own dummy variables?
Click to reveal answer
You can if you want to, but when Python identifies that you have a categorical variable, it creates dummy variables “behind the scenes” and shows the relevant estimates in the model output.