
2.9. Normal Distribution#
Another example of a data generating distribution is the Normal (or Gaussian) distribution.
2.9.1. Characteristics of the normal distritbution#
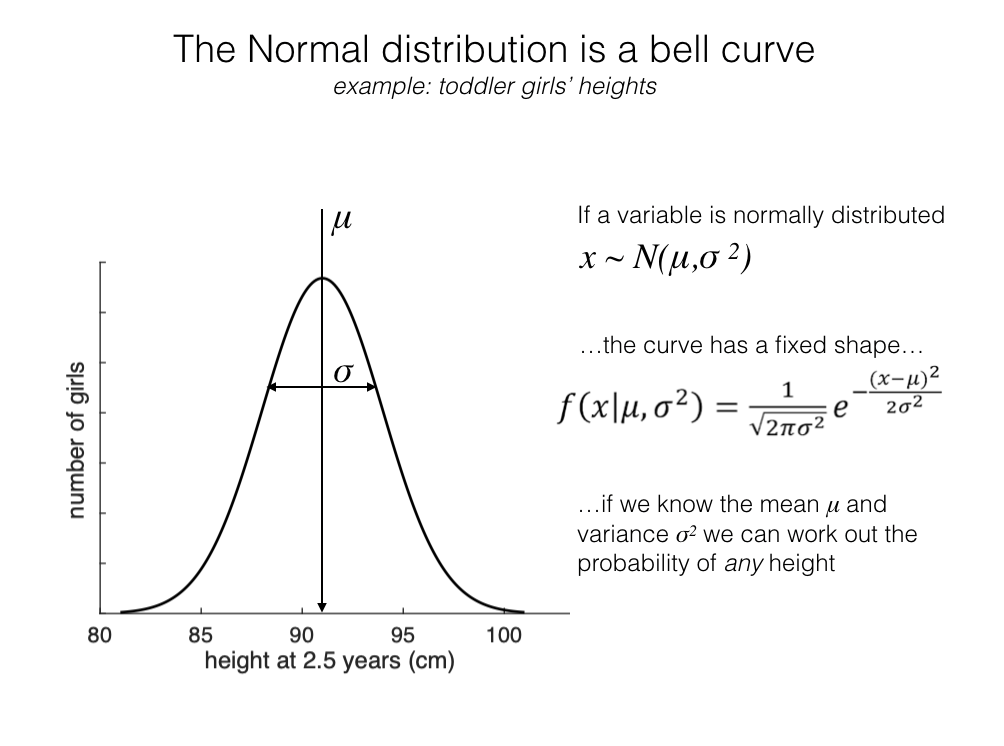
The normal distribution is a data distribution with a very particular ‘bell curve’ shape. It is not just any old symmetrical, unimodal distribution - it is described by an exact equation.
As we will see (later in the course), even the \(t\) distribution, another type of bell curve, can be distinguished from the normal distribution - and this distinction is important in statistical testing.
Normal distribution has two parameters#
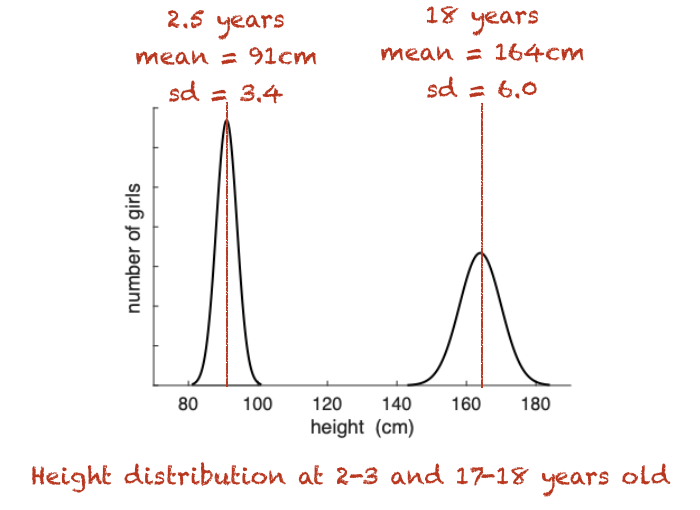
If some data (eg the heights of toddlers, or of adults) are normally distributed, that normal distribution can be summarized by two numbers or parameters:
the mean of the distribution, \(\mu\)
in the example below, the mean height of 18-year-olds is unsurprisingly higher than the mean height for 2-year-olds)
the standard deviation \(\sigma\)
in the example below, the spread of heights is larger for 18 year olds
Because we have the equation, once we know these two numbers we can estimate the full data distribution for heights (for example, I could tell you exactly how likely it is to be 95cm tall (to the nearest cm) as a toddler, or over 180cm as an adult woman)
Here is a video recap of the parameters of the normal distribution:
Notation#
When describing normally distributed data we sometimes use this notation:
To read this out loud we say:
“The height of adult women, \(x\), follows a Normal with mean 164cm and standard deviation 6.0cm”
Note that there is some inconsistency in how different authors use this notation; some people specify the standard deviation and others the variance. To minimize ambguity, I like to specify the standard deviation squared (ie the variance) as written above; this hopefully makes it obvious that \(6.0\) is the standard deviation and \(6.0^2\) is the variance
The Z-score#
To standardize data by Z-scoring, we take two steps:
subtract the mean (so the mean of the standardized dataset becomes zero)
divide by the standard deviation (so the standard deviation of the standardized dataset becomes 1)
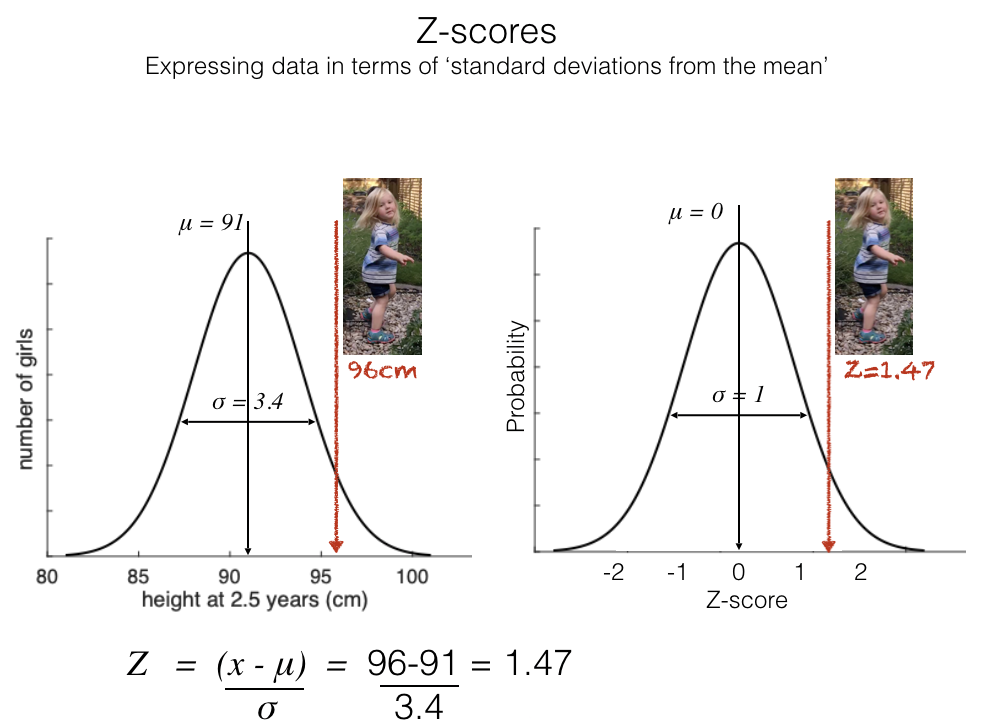
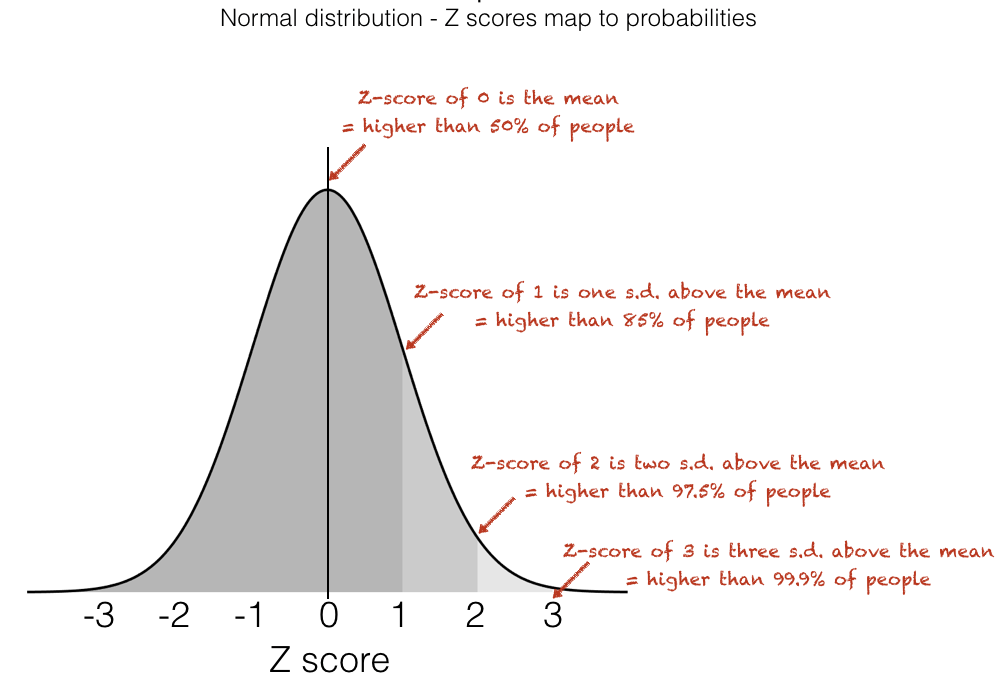
The result for normally distributed data is that the Z-scores translate directly into probabilities:
Here is a video recap about Z scores and finding probabilities from the normal distribution
Equation#
You can skip this subsection if you don’t fancy it
Here is a video about the maths of the bell curve, as described in the text below:
The equation of the bell curve is below. It has two parameters (numbers that vary between different normally distributed datasets): the mean \(\mu\) and the standard deviation \(\sigma\)
If we convert the data to Z-scores, we are standardizing the mean (to Zero) and sd (to 1), so the distribution of Z has no parameters that vary between datasets.
Looking closely at the simplifed form of the equation, we can see that the probability of a data value (or rather the corresponding Z-scores) is a function of the square of the Z-score, specifically \(e^{-Z^2}\).
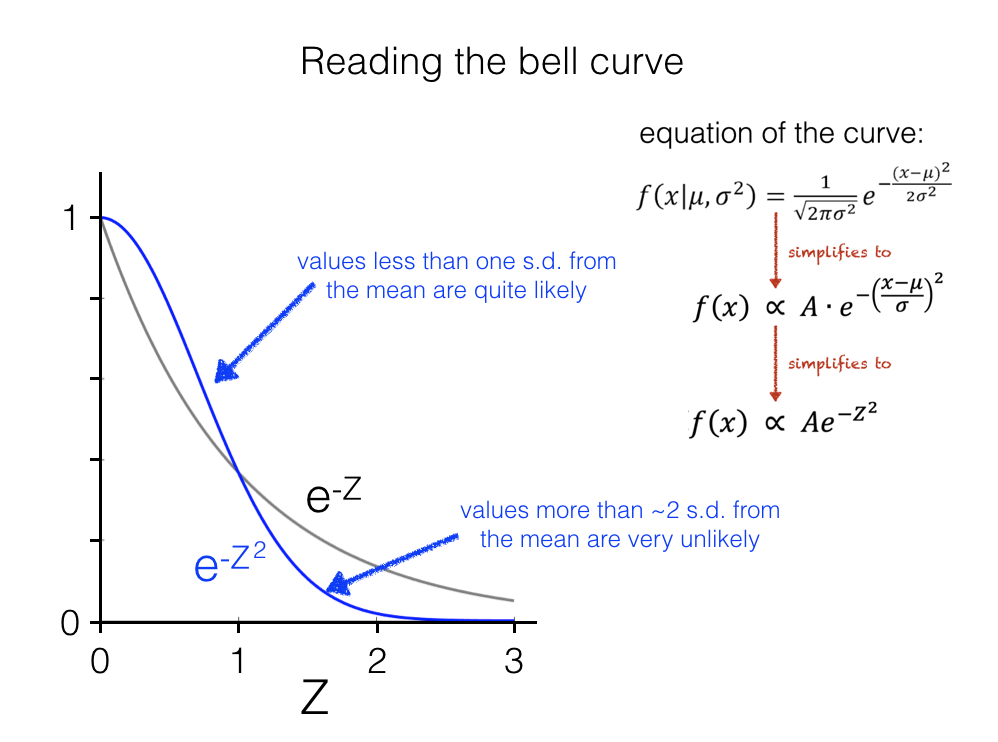
The probability of observing a data value falls off for data values further from the mean under the Normal distribution
Comparing to the more familiar exponential decay curve \(e^{-Z}\) we see:
Values less than one SD from the mean are quite likely (more likely under \(e^{-Z^2}\) than \(e^{-Z}\), because when \(Z<1\), then \(Z^2<Z\))
Values more than 1 SD from the mean are increasingly unlikely (less likely under \(e^{-Z^2}\) than \(e^{-Z}\), because when \(Z>1\), then \(Z^2>Z\))
As Z increases, the probability of observing a data value with that Z-score falls off rapidly, as \(Z^2 >> Z\) and \(e^{-Z^2}\) rapidly becomes tiny
This is what gives the normal distributions its thin tails
it means that if we try to fit a normal distribution to a dataset with an outlier, we end up estimating a very large standard deviation - because we can’t fit a normal that says one of our (say) 10 datapoints should occur only one in a million times (equivalent Z score of 4.75)
2.9.2. How do we know if data are normally distributed?#
Here is a video covering different approaches to evaluating whether data are drawn from a normal distribution:
For large samples we can plot a histogram and compare to the best-fitting normal. There are also statistical tests to determine whether data are normally distributed (but these are not covered here).
For smaller samples it is generally difficult to be confident that data are normally distributed. We can tell if data are strongly non normal by either:
Plotting the data (although note even this isn’t very helpful for small samples)
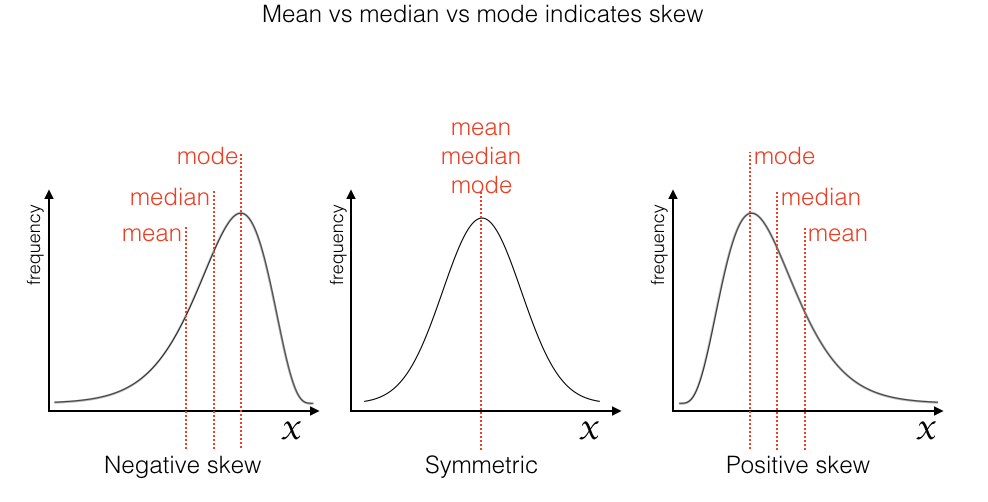
Comparing the mean, median and mode to detect skew (normal data are symmetrical, not skewed)
It is also worth noting that many quantities in nature are normally distributed, and measurement noise (from scientific instruments, surveys etc) is often also normally distributed. The reason for this is that any variable which is the sum of the effects of many independent causes tends to follow a normal distribution; the following video attempts to give you an intuition for why this is the case:
A final case in which we could be confident that data in a small sample are normally distributed are cases in which there is a theoretical argument that the data should be normal, based on the Central Limit Theorem. Very roughly, the Central Limit Theorem explains that when a data value results from the summation of many independent influences (eg the influence of many genes on height, or the effect of a ball bouncing left- or right many times on a Galton board) the resulting data values follow a normal distribution.
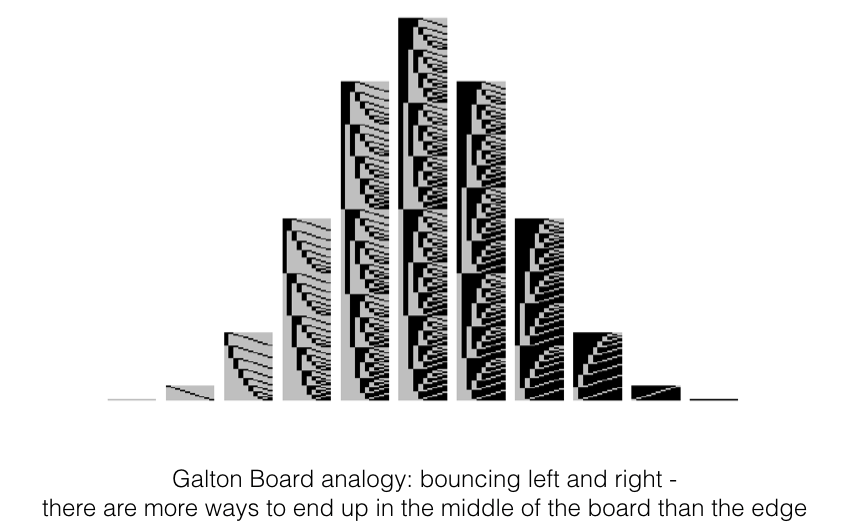
The Central Limit Theorem will be covered in more detail later in the course.