
3.7. Independent samples t-test#
3.7.1. Set up Python libraries#
As usual, run the code cell below to import the relevant Python libraries
# Set-up Python libraries - you need to run this but you don't need to change it
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas as pd
import seaborn as sns
sns.set_theme(style='white')
import statsmodels.api as sm
import statsmodels.formula.api as smf
3.7.2. Example#

Below we have data on the average weight, in grams, of apples from each of 20 apple trees.
10 of the trees received MiracleGro fertilizer and the other 10 received Brand X.
Test the hypothesis that the trees given MiracleGro produced heavier apples.
Inspect the data#
The data are provided in a text (.csv) file.
Let’s load the data as a Pandas dataframe, and plot them to get a sense for their distribution (is it normal?) and any outliers
# load the data and have a look
apples = pd.read_csv('https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook_2024/main/data/AppleWeights.csv')
apples
| Fertilizer | meanAppleWeight | |
|---|---|---|
| 0 | BrandX | 172 |
| 1 | BrandX | 165 |
| 2 | BrandX | 175 |
| 3 | BrandX | 164 |
| 4 | BrandX | 165 |
| 5 | BrandX | 157 |
| 6 | BrandX | 183 |
| 7 | BrandX | 186 |
| 8 | BrandX | 191 |
| 9 | BrandX | 173 |
| 10 | MiracleGro | 164 |
| 11 | MiracleGro | 198 |
| 12 | MiracleGro | 184 |
| 13 | MiracleGro | 200 |
| 14 | MiracleGro | 180 |
| 15 | MiracleGro | 189 |
| 16 | MiracleGro | 177 |
| 17 | MiracleGro | 170 |
| 18 | MiracleGro | 192 |
| 19 | MiracleGro | 193 |
| 20 | MiracleGro | 187 |
| 21 | MiracleGro | 176 |
Let’s plot the data and see if they look Normally distributed.
As we saw in the session on plotting, a good choice here will be a KDE plot (to get an estimate of the shape of the distribution) and a rug plot (individual data values as the KDE plot is based on only a small sample)
sns.kdeplot(data=apples, x='meanAppleWeight', hue='Fertilizer', fill=True)
sns.rugplot(data=apples, x='meanAppleWeight', hue='Fertilizer', height=0.1)
plt.xlabel("Mean weight of apples (g)", fontsize = 12)
plt.ylabel("Density", fontsize = 12)
plt.show()
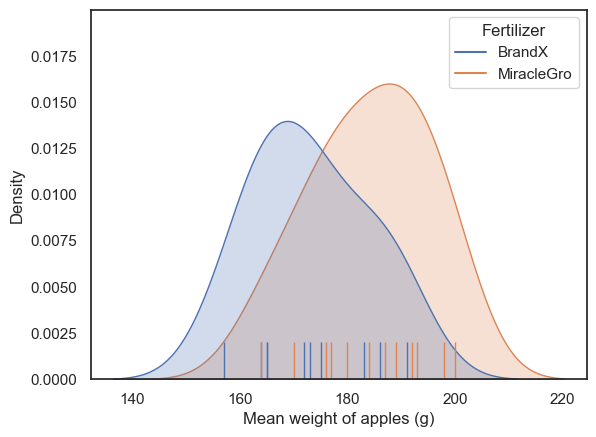
It looks like both distributions are unimodal but a bit skewed.
Typically, it would be hard to say if the data are really non-normal due to the small number of data points (the apparent skew could be a fluke). By default, I would err on the side of caution and use a non-parametric test.
However, in this particular case I am confident that the data in each sample are drawn from a normal distribution because each data point represents the mean of a large sample (the weights of all apples on one tree) and such means are always normally distributed due to the Central Limit theorem. There is a video explaining why here.
So we can go ahead and use a t-test.
Hypotheses#
\(\mathcal{H_o}\): the mean weight of apples is the same for trees fertilized with MiracleGro and Brand X
\(\mathcal{H_a}\): the mean weight of apples is greater for trees fertilized with MiracleGro
This is a one tailed test as the manufacturers of MiracleGro are only looking for an effect in one direction (evidence that MiracleGro is better!)
We will test at the \(\alpha = 0.05\) significance level
Descriptive statistics#
First, we obtain the relevant desriptive statistics. By relevant, I mean the ones that go into the equation for the t-test:
This would be the sample means \(\bar{x_1}\) and \(\bar{x_2}\), and the standard deviations for both samples (these feed into the pooled standard deviation \(s\)) and the sample size \(n\).
Remember, apples is our original Pandas dataframe:
display(apples)
| Fertilizer | meanAppleWeight | |
|---|---|---|
| 0 | BrandX | 172 |
| 1 | BrandX | 165 |
| 2 | BrandX | 175 |
| 3 | BrandX | 164 |
| 4 | BrandX | 165 |
| 5 | BrandX | 157 |
| 6 | BrandX | 183 |
| 7 | BrandX | 186 |
| 8 | BrandX | 191 |
| 9 | BrandX | 173 |
| 10 | MiracleGro | 164 |
| 11 | MiracleGro | 198 |
| 12 | MiracleGro | 184 |
| 13 | MiracleGro | 200 |
| 14 | MiracleGro | 180 |
| 15 | MiracleGro | 189 |
| 16 | MiracleGro | 177 |
| 17 | MiracleGro | 170 |
| 18 | MiracleGro | 192 |
| 19 | MiracleGro | 193 |
| 20 | MiracleGro | 187 |
| 21 | MiracleGro | 176 |
We obtain some commonly used descriptive statistics using the df.describe() method in pandas
apples.describe()
| meanAppleWeight | |
|---|---|
| count | 22.000000 |
| mean | 179.136364 |
| std | 12.123552 |
| min | 157.000000 |
| 25% | 170.500000 |
| 50% | 178.500000 |
| 75% | 188.500000 |
| max | 200.000000 |
We need the descriptive statistics separately for each fertilizer type.
We could use the separate dataframes that we created for plotting, but pandas has a handy method called df.groupby() that will do the job:
apples.groupby(["Fertilizer"]).describe()
| meanAppleWeight | ||||||||
|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | |
| Fertilizer | ||||||||
| BrandX | 10.0 | 173.100000 | 10.867382 | 157.0 | 165.00 | 172.5 | 181.00 | 191.0 |
| MiracleGro | 12.0 | 184.166667 | 11.101460 | 164.0 | 176.75 | 185.5 | 192.25 | 200.0 |
It does look like the mean weight of apples from the MiracleGro trees is higher, but is the difference statistically significant?
Carry out the test#
We carry out an independent samples t-test using the function ttest_ind from scipy.stats, here loaded as stats
stats.ttest_ind(apples.query('Fertilizer=="MiracleGro"').meanAppleWeight,
apples.query('Fertilizer=="BrandX"').meanAppleWeight,
alternative='greater')
Ttest_indResult(statistic=2.350347501385599, pvalue=0.014564862730138283)
The inputs to stats.ttest are the two samples to be compared (the values in the meanAppleWeight column from our separated Pandas data frames apples_BrandX and apples_MiracleGro) and the argument alternative=’greater’, which tells the computer to run a one tailed test that mean of the first input apples.MiracleGro is greater than the second apples.BrandX.
The outputs are statistic (\(t=2.35\)) and pvalue (\(p=0.0146\)) - if this is less than our \(\alpha\) value 0.5, there is a significant difference.
Degrees of freedom#
In a scientific write-up we also need to report the degrees of freedom of the test. This tells us how many observations (data-points) the test was based on, corrected for the number of means we had to estimate from the data in order to do the test.
In the case of the independent samples t-test \(df = n_1 + n_2 - 2\) so in this case, df=(10+12-2)=20 and we can report out test results as:
\(t(20) = 2.35, p=0.0146\) (one-tailed)
Interpretation#
Our t value of 2.35 means that the difference in mean apple weights between MiracleGro and BrandX trees is 2.35 times the standard error (where \( SE = s \sqrt{\frac{1}{n_1}+\frac{1}{n_2}}\)).
Such a large difference (in the expected direction) would occur 0.0146 (1.46%) of the time due to chance if the null hypothesis were true (if MiracleGro was really no better than Brand X), hence the p value of 0.0146.
This diagram shows the expected distribution of t-values if the null were true, with our obtained t-value marked:
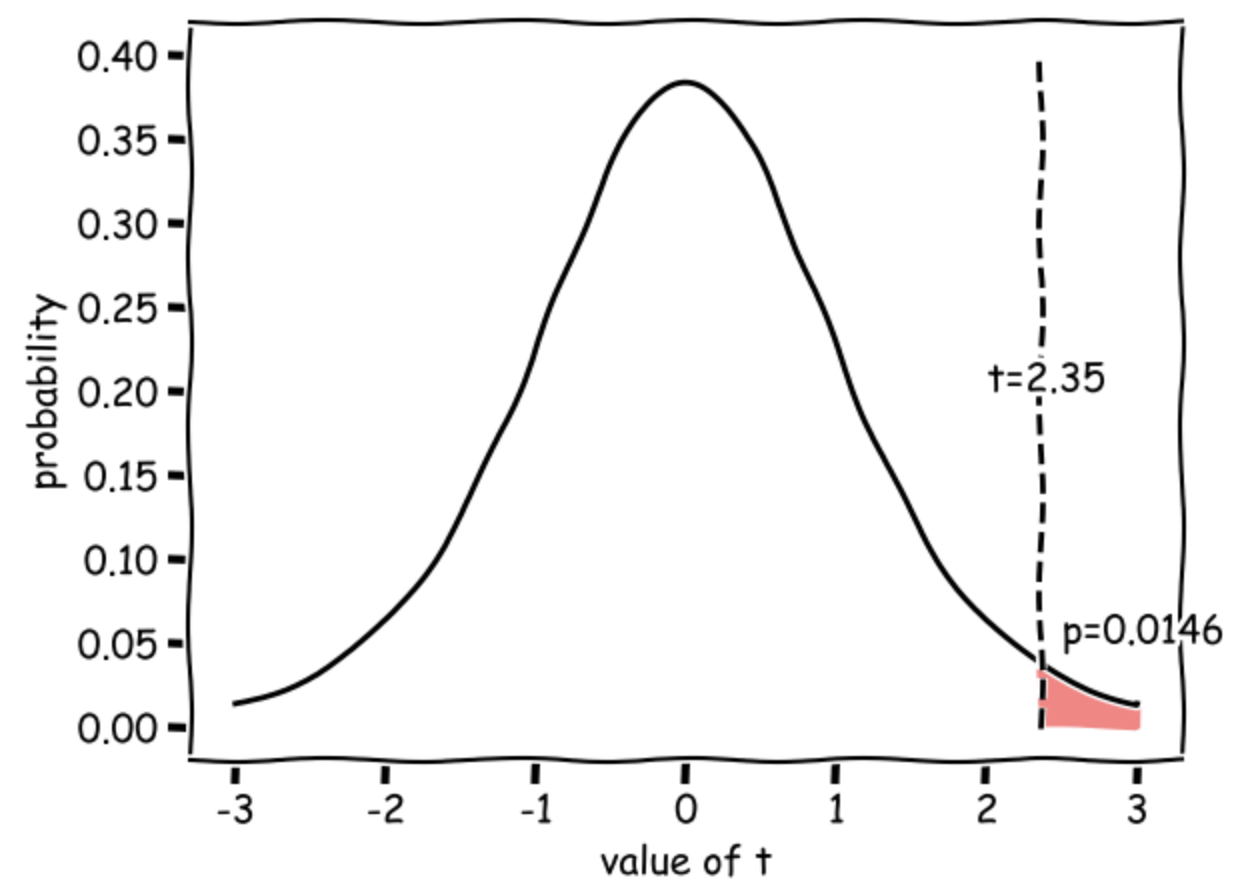
Draw conclusions#
As p<0.05 we conclude that the mean weight of apples on trees fertilized with MiracleGro is indeed greater than the mean weight of apples on trees fertilized with Brand X
3.7.3. Write-up#
Above, I walked you through how to run the t-test and why we make different choices.
In this section we revisit the analysis, but here we practice writing up our analysis in the correct style for a scientific report.
Replace the XXXs with the correct values!
We tested the hypothesis that the mean weight of apples produced by trees fertilized with MiracleGro was higher than for trees fertilized with Brand X.
The mean apple weight was measured for each of XX trees fertilized with MiracleGro (mean of mean apple weights over XX trees XXX.Xg, sd of mean apple weights over 100 trees, XXX.Xg) and XX trees fertilized with Brand X (mean over XX trees XXX.Xg, sd XXX.Xg).
apples = pd.read_csv('https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook_2024/main/data/AppleWeights.csv')
apples.groupby(["Fertilizer"]).describe()
| meanAppleWeight | ||||||||
|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | |
| Fertilizer | ||||||||
| BrandX | 10.0 | 173.100000 | 10.867382 | 157.0 | 165.00 | 172.5 | 181.00 | 191.0 |
| MiracleGro | 12.0 | 184.166667 | 11.101460 | 164.0 | 176.75 | 185.5 | 192.25 | 200.0 |
Theoretical considerations suggest that data for each group of trees should be drawn from a normal distribution: as individual data points were themselves the means of large samples (all apples from a given tree), these data points should follow a normal distribubtion due to the Central Limit Theorem. This was supported by a plot of the data:
sns.kdeplot(data=apples, x='meanAppleWeight', hue='Fertilizer', fill=True)
sns.rugplot(data=apples, x='meanAppleWeight', hue='Fertilizer', height=0.1)
plt.xlabel("Mean weight of apples (g)", fontsize = 12)
plt.ylabel("Density", fontsize = 12)
plt.show()
An independent samples t-test was therefore used to compare the means (alpha = XXX, XXX-tailed).
stats.ttest_ind(apples.query('Fertilizer=="MiracleGro"').meanAppleWeight,
apples.query('Fertilizer=="BrandX"').meanAppleWeight,
alternative='greater')
Ttest_indResult(statistic=2.350347501385599, pvalue=0.014564862730138283)
The weight of apples from the trees fertilized with MiracleGro was indeed found to be significantly higher: t(18) = 2.35, p=0.0146.
3.7.4. Exercises#
Can you work out how to run a two-tailed test on the data?
Info on the possible values for ‘alternative’ can be found on the scipy reference page
What happens to the p value if you run a two tailed test instead of one tailed? Is it more or less significant? Why?