
3.11. Tutorial exercises: Sampling#
In these exercises we again work with the Brexdex data
We are going to investigate how the sampling distribution of the mean depends on \(n\), the relationship between SEM and \(\sqrt{n}\), and how we assess whether a distribution, such as the sampling distribution of the mean, is Normal.
3.11.1. Set up Python libraries#
As usual, run the code cell below to import the relevant Python libraries
# Set-up Python libraries - you need to run this but you don't need to change it
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas as pd
import seaborn as sns
sns.set_theme(style='white')
import statsmodels.api as sm
import statsmodels.formula.api as smf
import warnings
warnings.simplefilter('ignore', category=FutureWarning)
3.11.2. Import and plot the data#
Let’s remind ourselves of the dataset we are working with
UKBrexdex=pd.read_csv('https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook_2025/main/data/UKBrexdex.csv')
UKBrexdex
| ID_code | score | |
|---|---|---|
| 0 | 186640 | 53 |
| 1 | 588140 | 90 |
| 2 | 977390 | 30 |
| 3 | 948470 | 42 |
| 4 | 564360 | 84 |
| ... | ... | ... |
| 9995 | 851780 | 81 |
| 9996 | 698340 | 45 |
| 9997 | 693580 | 51 |
| 9998 | 872730 | 78 |
| 9999 | 385642 | 88 |
10000 rows × 2 columns
What variables are in the dataset?
How many people are in the sample?
and let’s plot the data
sns.histplot(UKBrexdex.score, bins=range(101))
plt.xlabel('score on BrexDex')
plt.ylabel('frequency')
plt.show()
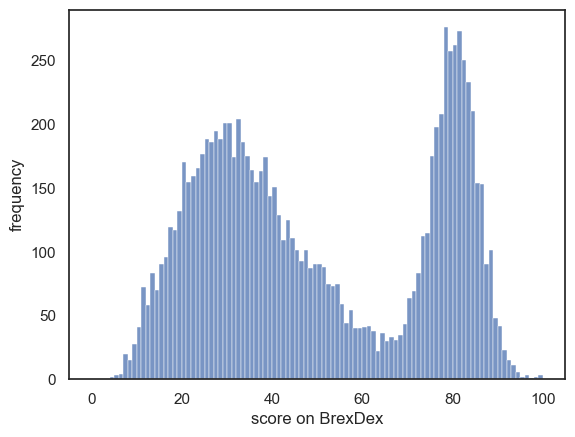
How would you describe this data?
write some text, including descritive statatistics, to describe the distribution of Brexdex scores in the UK population
3.11.3. Drawing a sample - recap#
We can draw a sample from our dataframe using df.sample(). The output of df.sample() is another dataframe (with \(n\) rows, where \(n\) is the sample size)
If we like, we can save this dataframe with a new name, like mySample
Create a new dataframe called
mySamplecontaining 10 people randomly sampled from the Brexdex datasetGet the mean score for this sample
# Your code here
3.11.4. Sampling distribution of the mean#
In general we are not interested in any specific sample, but just in working out how much random variation to expect between samples. To quantify this random variation we will need to generate a lot of samples (in a loop) but we don’t need to save each sample as a new dataframe, we can just save the sample mean from each sample into an array.
Let’s do this in steps:
First, get a sample of 10 people from the Brexdex distribution, find their mean score, and save it as a variable m - this should be a single line of code and if we print m, we should get a single number (somewhere near 50)
# Your code here
Now let’s make a loop to do this 50 times and save the mean of each sample into an array called m. When we print out m, we should now get an array of 50 numbers.
# I've included part of the code to get you started
# You will need to uncomment it
#m = np.zeros(50)
#for i in range(len(m)):
# Your code here
#m
Change the code above to get
100 samples of size 10
10 samples of size 100
Finally, let’s get the sample means for 10000 samples of size 50 and plot them on a histogram
# Your code here
#sns.histplot(m)
#plt.xlabel('sample mean')
#plt.show()
3.11.5. Standard error of the mean#
The standard error of the mean is the standard deviation of the sampling distribution of the mean.
Let’s work out the SEM from the distribution of sample means we just generated:
# m.std()
The SEM can also be calculated as $\( SEM = \frac{\sigma}{\sqrt{n}} \)$
# calculate the standard deviation of the Brexdex data
# sigma =
# n is the SAMPLE size
n=50
# Fill in the equation for the SEM
# Your code here
Hopefully the two values match well.
3.11.6. Shape of the sampling distribution#
Here we explore the shape of the sampling distribution of the mean
Sampling distribution of the mean when \(n\) is small#
Let’s start by simulating what the sampling distribution of the mean looks like for small values of \(n\) - starting with \(n=1\)
\(n=1\)#
Write some code to draw 10,000 samples with n=1, obtain the mean of each sample, and plot the means.
Think
Before you run it, think: what will this ‘sampling distribution of the mean’ look like?
# Your code here!
# Note this can be copied from examples earlier in the chapter
nSamples = 10000 # we will draw 10,000 samples
samplesize=1 # each sample contains n people
# make an empty array 'm' to store the means
# Make a loop to get the samples and store their means in m
# sns.histplot(m)
# plt.xlabel('sample mean')
# plt.show()
In fact when \(n=1\), the sample mean is simply the value of the (one) person in the sample’s score, so the sampling distribution of the mean is exactly the sample data distribution
\(n=2\)#
Write some code to draw 10,000 samples with n=2, obtain the mean of each sample, and plot the means.
# Your code here!
# Should be the same as the previous one but with a different n
Hopefully you have noticed a middle peak emerging.
Think-
A simple summary of the Brexdex distribution is that people are either pre-Brexit (belonging to the lower mode of the distribution, the hump of scores below 50%), or they are against Brexit (belonging to the upper mode).
If we draw a sample of \(n=2\), there are four possible outomes:
pro-pro
pro-against
against-pro
against-against
Case 1 yields low scores, case 4 yields high scores, and cases 2 and 3 yield intermediate scores.
How does this relate to the simulated sampling distribution of the mean you plotted?
\(n = 3,4,5\)#
As \(n\) increases, we rapidly see a unimodal, bell-curve-like shape emerging
Write some code to simulate the sampling distribution of the mean for 10,000 samples each of \(n=3,4,5\) and plot a histogram of the sample means for each value of \(n\). Organise these plots as subplots next to or above each other (you decide which is more informative)
To do this, you will need to use a double for-loop. I have completed some parts of the code to get you started.
To compare the sampling distributions effectively, students should plot them above eachother and match the scales on the x-axis
# Note this can be copied from examples in chapter 0 ("prepwork")
nSamples = 10000 # we will draw 10,000 samples
samplesize=[3,4,5] # each sample contains n people
for j in range(len(samplesize)):
m=np.empty(nSamples) # make an array to store the means
for i in range(nSamples):
pass # This is a placeholder, delete it!
# Your code here to fill in m with sample means
#plt.subplot(3,1,j+1)
#sns.histplot(m, bins=range(0,100,5))
#plt.xlabel('sample mean')
#plt.tight_layout()
#plt.show()
3.11.7. SEM is proportional to \(\frac{1}{\sqrt{n}}\)#
The standard error of the mean, which is the width of the sampling distribution of the mean, is inversely proportional to the square root of the sample size \(n\)
Using the double loop, as above, we can plot the SEM calculated in two ways:
as the standard deviation of the simulated sampling distribution of the mean
From the equation
… for a range of values of n
Complete the code block below:
nSamples = 100 # we will draw 100 samples at each samplesize
samplesizes=range(1,100) # try all values of n from 1 to 100
simulatedSEM=np.zeros(len(samplesizes))
calculatedSEM=np.zeros(len(samplesizes))
for j in range(len(samplesizes)):
m=np.zeros(nSamples) # make an array to store the means
for i in range(nSamples):
# Your code here to fill in m with sample means
pass # This is a placeholder, delete it!
simulatedSEM[j] = # your code here
calculatedSEM[j] = # your code here
#plt.plot(samplesizes, calculatedSEM, 'r')
#plt.plot(samplesizes, simulatedSEM, 'k.-')
#plt.xlabel('sample mean')
#plt.ylabel('SEM')
#plt.tight_layout()
#plt.show()
Cell In[13], line 13
simulatedSEM[j] = # your code here
^
SyntaxError: invalid syntax
3.11.8. When does the CLT apply?#
The Central Limit Theorem states that the sampling distribution of the mean is estimated by \(\mathcal{N}(\bar{x},\frac{s}{\sqrt{n}})\) when \(n\) is large
But how large is large enough?
A good rule of thumb is that the Central Limit Theorem applies for \(n>50\), and a larger \(n\) is required for a roughly normal sampling distribution when the data distribution is grossly non-normal (such as the bimodal Brexdex distribution).
In reality, the normal distribution becomes a closer and closer fit tot the sampling distribution of the mean as \(n\) gets larger
\(n=100\)#
Let’s start with a value of \(n\) for which the central limit theorem should definitely apply, \(n=100\)
Now, we work out the mean and SEM that would be predicted for the sampling distribution of the mean, if the central limit theorem applied.
Finally we compare the predicted normal distribution to the simulated sampling distribution of the mean in a plot
Note - The code to get the normal curve and histogram to match in scale is a bit fiddly, this was covered in the tutorial exercises last week
# first simulate the sampling distribution of the mean for 10,000 samples
nSamples = 10000
samplesize = 100
m=np.empty(nSamples) # make an array to store the means
binwidth=0.1
for i in range(nSamples):
sample = UKBrexdex.sample(n=samplesize, replace=False)
m[i]=sample.score.mean()
sns.histplot(m, bins=np.arange(40,60,binwidth))
# now work out the expected normal distribution
mu = UKBrexdex.score.mean()
sigma = UKBrexdex.score.std()
SEM = sigma/(samplesize**0.5)
x = np.arange(40,60,binwidth) # x axis values - you may wat to change these once you have tried plotting it
p = stats.norm.pdf(x,mu,SEM)
freq = p*nSamples*binwidth # exected frequency in each ibn is probability of the bin * total nSamples * bin width
plt.plot(x,freq,'r')
plt.xlabel('sample mean')
plt.show()
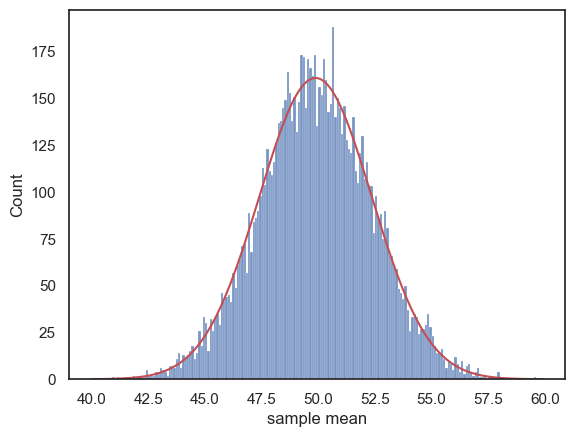
This is clearly quite a good fit.
Now try changing the samplesize, \(n\), in the code block above, to \(n=4\) (hint: change the histogram bins and x-axis values to np.arange(0,100,binwidth), and change binwidth to 1)
Hopefully, you can see that although the histogram on its own looked quite normal, it is actually not a great fit to the normal distribution we would expect if the Central Limit Theorem applied - the peak is too flat and there are fewer sample means out in the tails than we would expect - the distribution looks like a piece of Toblerone

Q-Q plot#
The differences in the peak and tails of the distribution can be hard to spot on a histogram/Normal plot as above.
A type of plot designed to make these clearer exists - it is called a Q-Q (quantile-quantile) plot. In the Q-Q plot, we plot the quantiles of the data distribution (in this case our 10,000 simulated sample means) against the quantiles of the normal distribution.
If our data distribution was normal, the points would all fall on a straight line, but here we see the deviation at the tails of the distribution, reflecting the difference between the triangular tails of the simulated sampling distribution as opposed to the finely tapered tails of the normal distribution.
# first simulate the sampling distribution of the mean for 10,000 samples
nSamples = 10000
samplesize = 100
m=np.empty(nSamples) # make an array to store the means
binwidth=0.1
for i in range(nSamples):
sample = UKBrexdex.sample(n=samplesize, replace=False)
m[i]=sample.score.mean()
# Now make the Q-Q plot
stats.probplot(m, plot=plt)
plt.show()
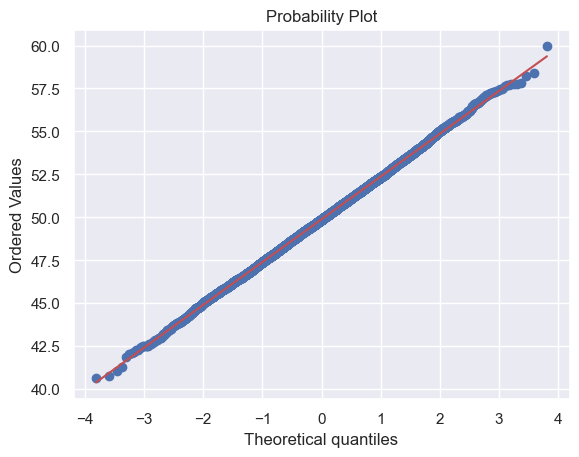
Try changing
samplesize(\(n\)) back to smaller values (\(n=2,3,4\)) or larger value such as (\(n=10,100\)) in the code block above and remaking the Q-Q plot.
You should see the tails of the sampling distribution (in both the histogram and the Q-Q plot) start to match the normal distribution
Try setting \(n=2\) in the code block above and remaking the Q-Q plot.
You should see the funny three-peak histogram - how is the shape of the histogram reflected in the Q-Q plot?