12.10. Loading data from a .csv file#
This section covers how to load data from a csv file saved on your own computer
You need to do this for the hand-in assignment set in 3rd week so make sure you try it, and check with your tutor in class if stuck.
#Set-up Python libraries - you need to run this but you don't need to change it
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas
import seaborn as sns
sns.set_theme()
sns.set_style('white')
In this course you have generally worked with data in Pandas.
To get the data into pandas, you usually run a readymade code block like this:
# load the data and have a look
heartRates = pandas.read_csv('https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook/main/data/HeartRates.csv')
display(heartRates)
| cookery | horror | |
|---|---|---|
| 0 | 60.4 | 72.9 |
| 1 | 53.9 | 57.0 |
| 2 | 54.4 | 68.3 |
| 3 | 60.0 | 57.4 |
| 4 | 67.7 | 58.7 |
| 5 | 56.2 | 47.0 |
| 6 | 61.9 | 71.8 |
| 7 | 58.9 | 62.1 |
| 8 | 65.6 | 68.6 |
| 9 | 54.6 | 73.8 |
| 10 | 85.2 | 93.1 |
| 11 | 87.8 | 94.8 |
| 12 | 90.5 | 111.4 |
| 13 | 92.7 | 89.7 |
| 14 | 85.4 | 97.4 |
| 15 | 77.5 | 90.9 |
| 16 | 81.3 | 83.9 |
| 17 | 79.7 | 86.9 |
| 18 | 96.8 | 90.1 |
| 19 | 81.9 | 75.4 |
Let’s take a closer look at that.
You are using a function called pandas.read_csv()
Inside the brackets is a URL for an online file repository (my Github if you are interested), from which the file will be read.
I place all the datafiles for the course on my online repository so I can edit them as needed. However, in ‘real life’ your data wouldn’t be on my github, they would be in a csv file on your own computer.
Download the datafile CloudSeeding.csv from this week’s page on Canvas and place it in the same directory (folder) as the downloaded copy of this Jupyter notebook
Now try running this code block:
clouds = pandas.read_csv('CloudSeeding.csv')
clouds
| status | rainfall | |
|---|---|---|
| 0 | Unseeded | 1202.6 |
| 1 | Unseeded | 830.1 |
| 2 | Unseeded | 372.4 |
| 3 | Unseeded | 345.5 |
| 4 | Unseeded | 321.2 |
| 5 | Unseeded | 244.3 |
| 6 | Unseeded | 163.0 |
| 7 | Unseeded | 147.8 |
| 8 | Unseeded | 95.0 |
| 9 | Unseeded | 87.0 |
| 10 | Unseeded | 81.2 |
| 11 | Unseeded | 68.5 |
| 12 | Unseeded | 47.3 |
| 13 | Unseeded | 41.1 |
| 14 | Unseeded | 36.6 |
| 15 | Unseeded | 29.0 |
| 16 | Unseeded | 28.6 |
| 17 | Unseeded | 26.3 |
| 18 | Unseeded | 26.1 |
| 19 | Unseeded | 24.4 |
| 20 | Unseeded | 21.7 |
| 21 | Unseeded | 17.3 |
| 22 | Unseeded | 11.5 |
| 23 | Unseeded | 4.9 |
| 24 | Unseeded | 4.9 |
| 25 | Unseeded | 1.0 |
| 26 | Seeded | 2745.6 |
| 27 | Seeded | 1697.8 |
| 28 | Seeded | 1656.0 |
| 29 | Seeded | 978.0 |
| 30 | Seeded | 703.4 |
| 31 | Seeded | 489.1 |
| 32 | Seeded | 430.0 |
| 33 | Seeded | 334.1 |
| 34 | Seeded | 302.8 |
| 35 | Seeded | 274.7 |
| 36 | Seeded | 274.7 |
| 37 | Seeded | 255.0 |
| 38 | Seeded | 242.5 |
| 39 | Seeded | 200.7 |
| 40 | Seeded | 198.6 |
| 41 | Seeded | 129.6 |
| 42 | Seeded | 119.0 |
| 43 | Seeded | 118.3 |
| 44 | Seeded | 115.3 |
| 45 | Seeded | 92.4 |
| 46 | Seeded | 40.6 |
| 47 | Seeded | 32.7 |
| 48 | Seeded | 31.4 |
| 49 | Seeded | 17.5 |
| 50 | Seeded | 7.7 |
| 51 | Seeded | 4.1 |
OOh, it worked!
Subdirectories#
Say you have all your Jupyter Notebooks (including this one) in a nice tidy folder (or directory) called StatsClassWeek3 and you don’t want lots of messy csv files lying around in there.
No problem - in your file browser, go to the folder StatsClassWeek3 and cerate a new folder (or directory) called data. Place the csv file CloudSeeding.csv in the folder data
Now we run the following code:
clouds = pandas.read_csv('data/CloudSeeding.csv')
clouds
| status | rainfall | |
|---|---|---|
| 0 | Unseeded | 1202.6 |
| 1 | Unseeded | 830.1 |
| 2 | Unseeded | 372.4 |
| 3 | Unseeded | 345.5 |
| 4 | Unseeded | 321.2 |
| 5 | Unseeded | 244.3 |
| 6 | Unseeded | 163.0 |
| 7 | Unseeded | 147.8 |
| 8 | Unseeded | 95.0 |
| 9 | Unseeded | 87.0 |
| 10 | Unseeded | 81.2 |
| 11 | Unseeded | 68.5 |
| 12 | Unseeded | 47.3 |
| 13 | Unseeded | 41.1 |
| 14 | Unseeded | 36.6 |
| 15 | Unseeded | 29.0 |
| 16 | Unseeded | 28.6 |
| 17 | Unseeded | 26.3 |
| 18 | Unseeded | 26.1 |
| 19 | Unseeded | 24.4 |
| 20 | Unseeded | 21.7 |
| 21 | Unseeded | 17.3 |
| 22 | Unseeded | 11.5 |
| 23 | Unseeded | 4.9 |
| 24 | Unseeded | 4.9 |
| 25 | Unseeded | 1.0 |
| 26 | Seeded | 2745.6 |
| 27 | Seeded | 1697.8 |
| 28 | Seeded | 1656.0 |
| 29 | Seeded | 978.0 |
| 30 | Seeded | 703.4 |
| 31 | Seeded | 489.1 |
| 32 | Seeded | 430.0 |
| 33 | Seeded | 334.1 |
| 34 | Seeded | 302.8 |
| 35 | Seeded | 274.7 |
| 36 | Seeded | 274.7 |
| 37 | Seeded | 255.0 |
| 38 | Seeded | 242.5 |
| 39 | Seeded | 200.7 |
| 40 | Seeded | 198.6 |
| 41 | Seeded | 129.6 |
| 42 | Seeded | 119.0 |
| 43 | Seeded | 118.3 |
| 44 | Seeded | 115.3 |
| 45 | Seeded | 92.4 |
| 46 | Seeded | 40.6 |
| 47 | Seeded | 32.7 |
| 48 | Seeded | 31.4 |
| 49 | Seeded | 17.5 |
| 50 | Seeded | 7.7 |
| 51 | Seeded | 4.1 |
The slash in the commmand pandas.read_csv('data/CloudSeeding.csv') just means that data is the name of a folder and CloudSeeding.csv is inside that folder
Colab#
If you are on Colab you will need to upload the data file before you can read it in.
To do this you click the file icon at the left of your notebook
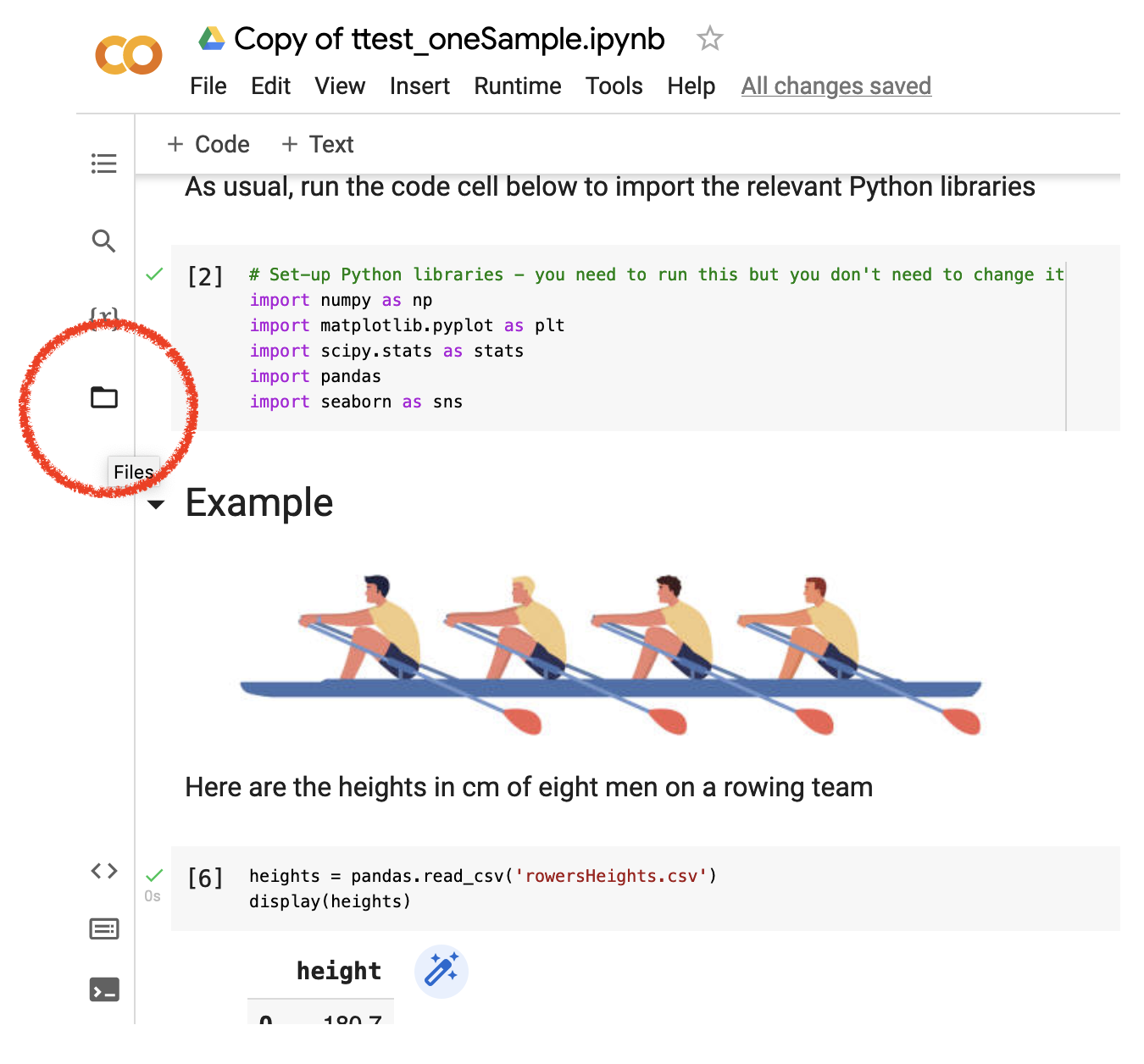
… a file panel opens.
Click the upload button at the top of this panel
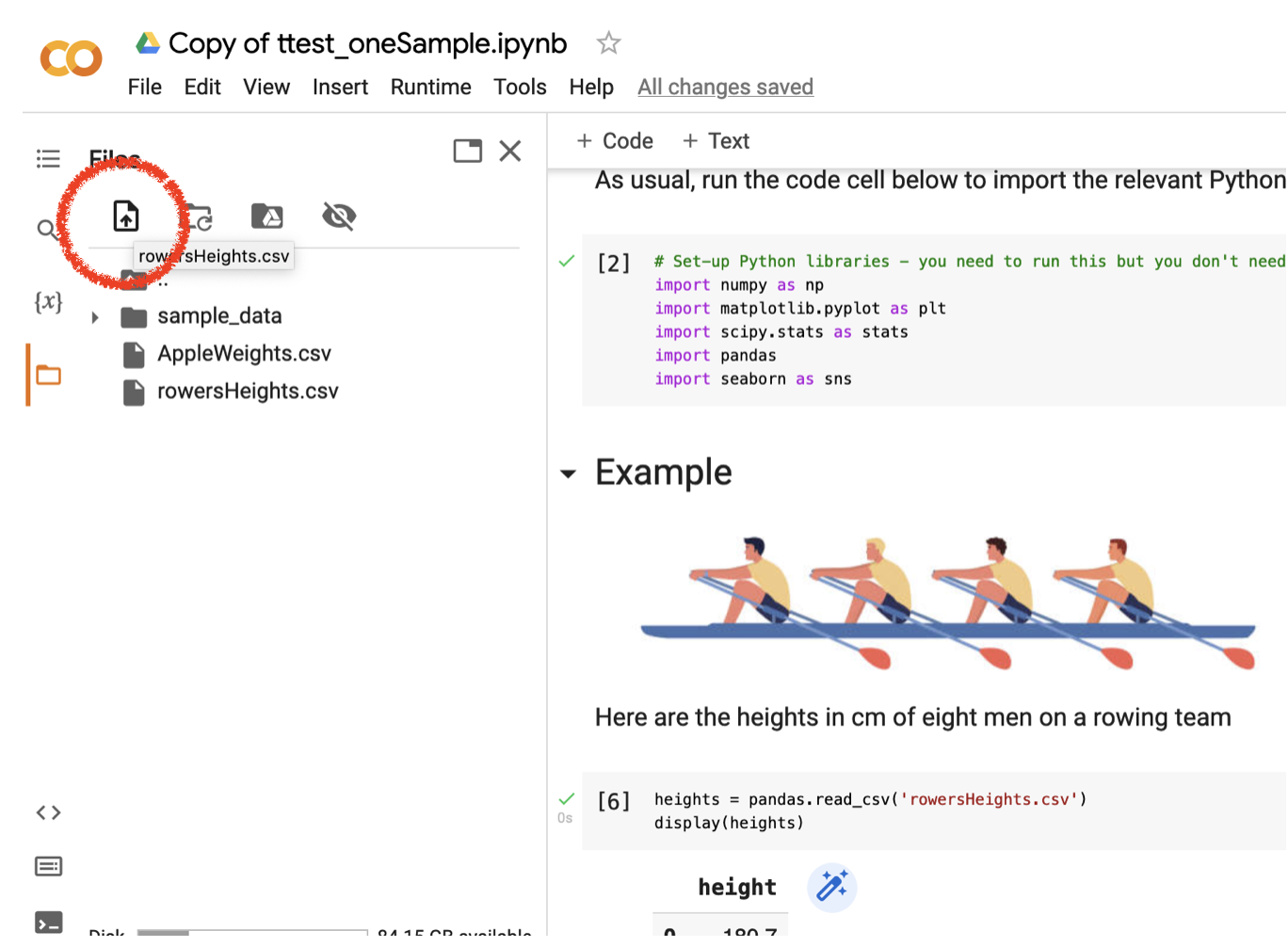
… a file browser opens. Select the CSV file from where you downloaded it on your own computer (if you are not sure where it went, it might have gone in your Downloads folder!).
The file appears in the file panel and can now be loaded from your Colab notebook as per my instructions above