
10.6. Permutation test for correlation#
In the previous examples we used permutation testing to assess the significance of a difference between groups (difference of means or mean difference).
Permutation testing can also be used to assess the statistical significance of a correlation.
As a reminder, a correlation can occur only in paired designs, as when two variables are correlated, it means that an individual’s score on one variable is related to their score on the other variable.
Correlations can be interesting in themselves (do students who score highly on English tests also score highly on maths tests?; do people who eat more broccli have greater bone density?).
They can also reflect the fact that experimental measures often depend on factors other than the one we are manipulating (sometimes called confounding factors), which are what we try to control for by using a paired design. For example if we are interested in whether men earn more than women, we might use a paired design comparing brothers and sisters to take into account the very important effects of parental occupation and education on earnings which mean that high-earning brothers often have high-earning sisters. The fact that brothers’ and sisters’ earnings are correlated actually reflects the confounds that we want to ‘cancel out’ by using a paired design to test gender differences.
Set up Python libraries#
As usual, run the code cell below to import the relevant Python libraries
# Set-up Python libraries - you need to run this but you don't need to change it
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas
import seaborn as sns
Toy example#
[A toy example is an example with a very small dataset, just to show how it works]
We are interested in whether people who eat more broccoli have higher IQs.
The following made-up data give weekly broccoli consumption in grams and IQ for 25 individuals:
broccoli = pandas.read_csv('https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook/main/data/broccoli.csv')
broccoli
---------------------------------------------------------------------------
ConnectionResetError Traceback (most recent call last)
File ~/opt/anaconda3/lib/python3.9/urllib/request.py:1346, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1345 try:
-> 1346 h.request(req.get_method(), req.selector, req.data, headers,
1347 encode_chunked=req.has_header('Transfer-encoding'))
1348 except OSError as err: # timeout error
File ~/opt/anaconda3/lib/python3.9/http/client.py:1285, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1284 """Send a complete request to the server."""
-> 1285 self._send_request(method, url, body, headers, encode_chunked)
File ~/opt/anaconda3/lib/python3.9/http/client.py:1331, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1330 body = _encode(body, 'body')
-> 1331 self.endheaders(body, encode_chunked=encode_chunked)
File ~/opt/anaconda3/lib/python3.9/http/client.py:1280, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1279 raise CannotSendHeader()
-> 1280 self._send_output(message_body, encode_chunked=encode_chunked)
File ~/opt/anaconda3/lib/python3.9/http/client.py:1040, in HTTPConnection._send_output(self, message_body, encode_chunked)
1039 del self._buffer[:]
-> 1040 self.send(msg)
1042 if message_body is not None:
1043
1044 # create a consistent interface to message_body
File ~/opt/anaconda3/lib/python3.9/http/client.py:980, in HTTPConnection.send(self, data)
979 if self.auto_open:
--> 980 self.connect()
981 else:
File ~/opt/anaconda3/lib/python3.9/http/client.py:1454, in HTTPSConnection.connect(self)
1452 server_hostname = self.host
-> 1454 self.sock = self._context.wrap_socket(self.sock,
1455 server_hostname=server_hostname)
File ~/opt/anaconda3/lib/python3.9/ssl.py:501, in SSLContext.wrap_socket(self, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, session)
495 def wrap_socket(self, sock, server_side=False,
496 do_handshake_on_connect=True,
497 suppress_ragged_eofs=True,
498 server_hostname=None, session=None):
499 # SSLSocket class handles server_hostname encoding before it calls
500 # ctx._wrap_socket()
--> 501 return self.sslsocket_class._create(
502 sock=sock,
503 server_side=server_side,
504 do_handshake_on_connect=do_handshake_on_connect,
505 suppress_ragged_eofs=suppress_ragged_eofs,
506 server_hostname=server_hostname,
507 context=self,
508 session=session
509 )
File ~/opt/anaconda3/lib/python3.9/ssl.py:1074, in SSLSocket._create(cls, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, context, session)
1073 raise ValueError("do_handshake_on_connect should not be specified for non-blocking sockets")
-> 1074 self.do_handshake()
1075 except (OSError, ValueError):
File ~/opt/anaconda3/lib/python3.9/ssl.py:1343, in SSLSocket.do_handshake(self, block)
1342 self.settimeout(None)
-> 1343 self._sslobj.do_handshake()
1344 finally:
ConnectionResetError: [Errno 54] Connection reset by peer
During handling of the above exception, another exception occurred:
URLError Traceback (most recent call last)
Cell In[2], line 1
----> 1 broccoli = pandas.read_csv('https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook/main/data/broccoli.csv')
2 broccoli
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/parsers/readers.py:912, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
899 kwds_defaults = _refine_defaults_read(
900 dialect,
901 delimiter,
(...)
908 dtype_backend=dtype_backend,
909 )
910 kwds.update(kwds_defaults)
--> 912 return _read(filepath_or_buffer, kwds)
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/parsers/readers.py:577, in _read(filepath_or_buffer, kwds)
574 _validate_names(kwds.get("names", None))
576 # Create the parser.
--> 577 parser = TextFileReader(filepath_or_buffer, **kwds)
579 if chunksize or iterator:
580 return parser
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/parsers/readers.py:1407, in TextFileReader.__init__(self, f, engine, **kwds)
1404 self.options["has_index_names"] = kwds["has_index_names"]
1406 self.handles: IOHandles | None = None
-> 1407 self._engine = self._make_engine(f, self.engine)
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/parsers/readers.py:1661, in TextFileReader._make_engine(self, f, engine)
1659 if "b" not in mode:
1660 mode += "b"
-> 1661 self.handles = get_handle(
1662 f,
1663 mode,
1664 encoding=self.options.get("encoding", None),
1665 compression=self.options.get("compression", None),
1666 memory_map=self.options.get("memory_map", False),
1667 is_text=is_text,
1668 errors=self.options.get("encoding_errors", "strict"),
1669 storage_options=self.options.get("storage_options", None),
1670 )
1671 assert self.handles is not None
1672 f = self.handles.handle
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/common.py:716, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
713 codecs.lookup_error(errors)
715 # open URLs
--> 716 ioargs = _get_filepath_or_buffer(
717 path_or_buf,
718 encoding=encoding,
719 compression=compression,
720 mode=mode,
721 storage_options=storage_options,
722 )
724 handle = ioargs.filepath_or_buffer
725 handles: list[BaseBuffer]
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/common.py:368, in _get_filepath_or_buffer(filepath_or_buffer, encoding, compression, mode, storage_options)
366 # assuming storage_options is to be interpreted as headers
367 req_info = urllib.request.Request(filepath_or_buffer, headers=storage_options)
--> 368 with urlopen(req_info) as req:
369 content_encoding = req.headers.get("Content-Encoding", None)
370 if content_encoding == "gzip":
371 # Override compression based on Content-Encoding header
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/common.py:270, in urlopen(*args, **kwargs)
264 """
265 Lazy-import wrapper for stdlib urlopen, as that imports a big chunk of
266 the stdlib.
267 """
268 import urllib.request
--> 270 return urllib.request.urlopen(*args, **kwargs)
File ~/opt/anaconda3/lib/python3.9/urllib/request.py:214, in urlopen(url, data, timeout, cafile, capath, cadefault, context)
212 else:
213 opener = _opener
--> 214 return opener.open(url, data, timeout)
File ~/opt/anaconda3/lib/python3.9/urllib/request.py:517, in OpenerDirector.open(self, fullurl, data, timeout)
514 req = meth(req)
516 sys.audit('urllib.Request', req.full_url, req.data, req.headers, req.get_method())
--> 517 response = self._open(req, data)
519 # post-process response
520 meth_name = protocol+"_response"
File ~/opt/anaconda3/lib/python3.9/urllib/request.py:534, in OpenerDirector._open(self, req, data)
531 return result
533 protocol = req.type
--> 534 result = self._call_chain(self.handle_open, protocol, protocol +
535 '_open', req)
536 if result:
537 return result
File ~/opt/anaconda3/lib/python3.9/urllib/request.py:494, in OpenerDirector._call_chain(self, chain, kind, meth_name, *args)
492 for handler in handlers:
493 func = getattr(handler, meth_name)
--> 494 result = func(*args)
495 if result is not None:
496 return result
File ~/opt/anaconda3/lib/python3.9/urllib/request.py:1389, in HTTPSHandler.https_open(self, req)
1388 def https_open(self, req):
-> 1389 return self.do_open(http.client.HTTPSConnection, req,
1390 context=self._context, check_hostname=self._check_hostname)
File ~/opt/anaconda3/lib/python3.9/urllib/request.py:1349, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1346 h.request(req.get_method(), req.selector, req.data, headers,
1347 encode_chunked=req.has_header('Transfer-encoding'))
1348 except OSError as err: # timeout error
-> 1349 raise URLError(err)
1350 r = h.getresponse()
1351 except:
URLError: <urlopen error [Errno 54] Connection reset by peer>
Let’s plot the data:
sns.scatterplot(data=broccoli, x='broccoli_g', y='IQ', alpha=0.5)
<AxesSubplot:xlabel='broccoli_g', ylabel='IQ'>
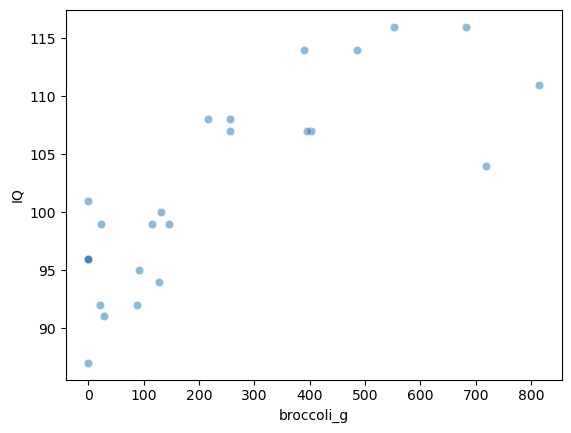
We can see that there does seem to be a correlation. Let’s calculate Pearson’s $r$
broccoli.corr()
| broccoli_g | IQ | |
|---|---|---|
| broccoli_g | 1.000000 | 0.801153 |
| IQ | 0.801153 | 1.000000 |
The correlation is 0.80, which is actually very strong (remember they are made-up data!).
Is this result statistically significant?#
That is, would the result (a correlation of 0.80) be very unlikely to occur due to chance, if the null hypothesis were true?
To answer this question, we need to think about what the null hypothesis is.
The correlation tests for a relationship between broccoli consumption and IQ. The null hypothesis is that there is no such relationship.
Even if there was no relationship between broccoli consumption and IQ, it would sometimes happen that for 25 random people the ones with the highest IQ tend to also be the biggest broccoli-eaters, resulting in a positive correlation. The question is how often a positive correlation as large as $r$=0.80 would occur just due to chance. This will depend on the distriubtion in both broccoli consumption and IQ.
Obtaining the null distribution by permutation testing#
The sample tells us several interesting things about the parent distribution, regardless of whether broccoli consummption and IQ are related:
- Most people eat between 0 and 500g of broccoli a week
- Quite a few people eat 0g of broccoli (they never eat broccoli, basically)
It also tells us about some potential effects to do with the relationship between IQ and broccoli:
- the quantity of broccoli eaten seems to be higher for individuals with higher IQ
- none of the highest IQ people are the 0g of broccoli people
What we are going to do is shuffle the data around to create many new (re)samples preserving distribution within each variable (broccoli consumption and IQ - so for example there will always be 5 non-broccoli-eaters) but pairing the datapoints at random so one person’s IQ is matched with another person’s broccoli consumption.
Using these simulated (shuffled) datasets we will work out how often we get a correlation of 0.80 or more. This is equivalent to determining how likely our correlation is to have occurred due to chance.
Run the simulation#
To generate new simulated datasets, we will shuffle around the datapoints in our original dataset.
Which ones can we shuffle?
To generate each new simulated dataset, we will randomly shuffle the values for broccoli consumption, whilst leaving the IQs in place, to get a random re-pairing of the data
Here is one such shuffle, try running it a few times and watching how the resulting dataframe changes
broccoli_shuffled = broccoli.copy()
broccoli_shuffled['broccoli_g'] = np.random.permutation(broccoli.broccoli_g) # replace the column 'broccoli_g' with a random permutation of itself
broccoli_shuffled
| broccoli_g | IQ | |
|---|---|---|
| 0 | 146 | 87 |
| 1 | 20 | 91 |
| 2 | 255 | 101 |
| 3 | 255 | 92 |
| 4 | 682 | 96 |
| 5 | 0 | 95 |
| 6 | 131 | 92 |
| 7 | 88 | 94 |
| 8 | 92 | 96 |
| 9 | 719 | 99 |
| 10 | 815 | 99 |
| 11 | 0 | 96 |
| 12 | 22 | 99 |
| 13 | 216 | 108 |
| 14 | 553 | 100 |
| 15 | 395 | 107 |
| 16 | 114 | 114 |
| 17 | 0 | 107 |
| 18 | 485 | 108 |
| 19 | 390 | 104 |
| 20 | 402 | 107 |
| 21 | 128 | 114 |
| 22 | 28 | 116 |
| 23 | 0 | 116 |
| 24 | 0 | 111 |
Let’s get the correlation in the shuffled dataset:
np.corrcoef(broccoli_shuffled.broccoli_g, broccoli_shuffled.IQ)
array([[1. , 0.17030221],
[0.17030221, 1. ]])
Visualizing randoms shuffles in the broccoli data#
It’s not really obvious what has happened from looking at the dataframe, but let’s try plotting some shuffled data below
Below I generate 4 random shuffles of broccoli data, and plot the outcomes:
for n in range(3):
broccoli_shuffled = broccoli.copy() # work on a copy of the original dataframe
broccoli_shuffled['broccoli_g'] = np.random.permutation(broccoli_shuffled['broccoli_g']) # replace the column 'Pet' with a random permutation of itself
plt.subplot(2,2,n+1)
sns.scatterplot(data=broccoli_shuffled, x='broccoli_g', y='IQ', alpha=0.5)
# plot the original data in red
plt.subplot(2,2,4)
sns.scatterplot(data=broccoli, x='broccoli_g', y='IQ', color='r')
plt.tight_layout()
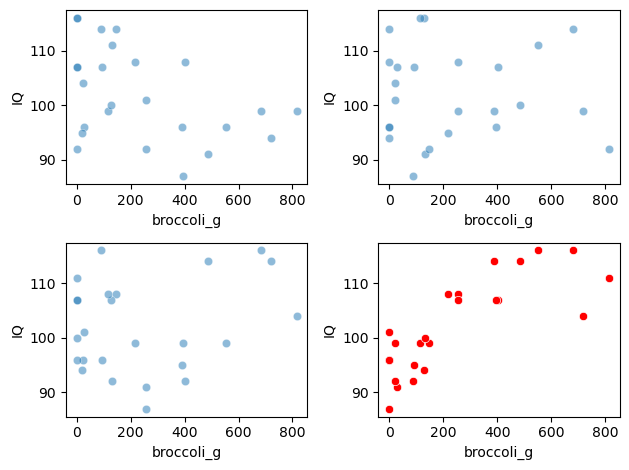
You can see that the relationship bbetween broccoli consumption and IQ looks less tight in the shuffled (blue) datasets.
Plot the null distribution for a large number of shuffles#
Now we can repeat the process for a large number of shuffles and get the correlation (Spearman’s $r$) for each shuffle. The distribution of these correlations is the null distribution to which our observed difference ($r$=0.80) is to be compared.
nReps = 10000 # (number of shuffles)
c = np.empty(nReps) # array to store mean difference for each shuffle
for i in range(nReps):
broccoli_shuffled = broccoli.copy() # work on a copy of the original dataframe
broccoli_shuffled['broccoli_g'] = np.random.permutation(broccoli['broccoli_g']) # replace the column 'Pet' with a random permutation of itself
tmp = np.corrcoef(broccoli_shuffled.broccoli_g, broccoli.IQ)
c[i] = tmp[0][1]
sns.histplot(c)
plt.show()
print('proportion >0.80 = ' + str(100*np.mean(c>0.80)) + '%')
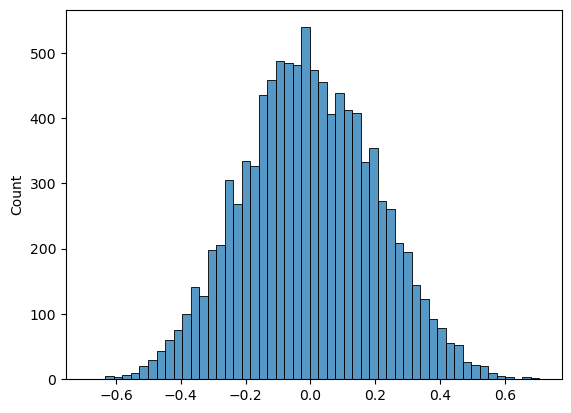
proportion >0.80 = 0.0%
The $𝑝$-value¶#
The probability that the test statistic (in this case, the correlation bbetween broccoli consumption and IQ) would be observed if the null hypothesis were true, is sometimes called the $𝑝$-value.
Our permutation test shows that the $𝑝$-value associated with the observed difference of means is basically zero- we never get a correlation of 0.80 in our 10,000 random shuffles.
The result is considered statistically significant if $𝑝$ is smaller than some predetermined level, known as $\alpha$. Usually $\alpha=0.05$ or $\alpha=0.05$ is used, so the result is significant if $p=0.05$ or $p=0.01$. Our result would be considered highly statistically significant.
Use a built in function#
Now you have seen how the permutation test works, we can learn how to run it more easily using the built in function scipy.stats.permutation_test
Syntax of stats.permutation_test#
As previously, we need to define a function that gets our test statsitic.
The numpy function df.corr() does part of the job, but it returns a 2-2 correlation matrix. To get the correlation we need, we then have to pick out the element in row 0 and column 1:
def correlate(x, y):
tmp = np.corrcoef(x,y)
c = tmp[0][1]
return c
Thereafter we have to run stats.permutation_test, but using the option permutation_type='pairings', which shuffles the data in such a way as to keep all the broccoli values in the broccoi column, but re-pair them with different people’s IQs in each shuffle.
Recap#
To run a permutation test on a correlation, we shuffled up all the pairings so each person’s IQ was paired with someone else’s broccoli consumption. We did not switch any datapoints from the broccoli column into the the IQ column (!).
For each shuffle we calculated the correlation between broccoli consumption and IQ
Permutation testing in this way gives us a null distribution for the correlation. Values of the correlation coefficient that occur rarely in the null distriubtion are considered statistically significant.
To run the permutation test with scipy.stats we need the option permutation_type='pairings'