
4.8. Python skills check#
You should work through this before the tutorial. The idea is for you to find the relevant code snippets int he worked examples you have just read, and modify them to work for your requirements here
Oxford weather station data#
We will work with historical data from the Oxford weather station

Set up Python libraries#
As usual, run the code cell below to import the relevant Python libraries
# Set-up Python libraries - you need to run this but you don't need to change it
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas
import seaborn as sns
sns.set_theme()
Load and inspect the data#
Let’s load some historical data about the weather in Oxford, from the file “OxfordWeather.csv”
weather = pandas.read_csv("https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook/main/data/OxfordWeather.csv")
display(weather)
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[2], line 1
----> 1 weather = pandas.read_csv("https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook/main/data/OxfordWeather.csv")
2 display(weather)
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/parsers/readers.py:912, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
899 kwds_defaults = _refine_defaults_read(
900 dialect,
901 delimiter,
(...)
908 dtype_backend=dtype_backend,
909 )
910 kwds.update(kwds_defaults)
--> 912 return _read(filepath_or_buffer, kwds)
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/parsers/readers.py:577, in _read(filepath_or_buffer, kwds)
574 _validate_names(kwds.get("names", None))
576 # Create the parser.
--> 577 parser = TextFileReader(filepath_or_buffer, **kwds)
579 if chunksize or iterator:
580 return parser
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/parsers/readers.py:1407, in TextFileReader.__init__(self, f, engine, **kwds)
1404 self.options["has_index_names"] = kwds["has_index_names"]
1406 self.handles: IOHandles | None = None
-> 1407 self._engine = self._make_engine(f, self.engine)
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/parsers/readers.py:1661, in TextFileReader._make_engine(self, f, engine)
1659 if "b" not in mode:
1660 mode += "b"
-> 1661 self.handles = get_handle(
1662 f,
1663 mode,
1664 encoding=self.options.get("encoding", None),
1665 compression=self.options.get("compression", None),
1666 memory_map=self.options.get("memory_map", False),
1667 is_text=is_text,
1668 errors=self.options.get("encoding_errors", "strict"),
1669 storage_options=self.options.get("storage_options", None),
1670 )
1671 assert self.handles is not None
1672 f = self.handles.handle
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/common.py:716, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
713 codecs.lookup_error(errors)
715 # open URLs
--> 716 ioargs = _get_filepath_or_buffer(
717 path_or_buf,
718 encoding=encoding,
719 compression=compression,
720 mode=mode,
721 storage_options=storage_options,
722 )
724 handle = ioargs.filepath_or_buffer
725 handles: list[BaseBuffer]
File ~/opt/anaconda3/lib/python3.9/site-packages/pandas/io/common.py:373, in _get_filepath_or_buffer(filepath_or_buffer, encoding, compression, mode, storage_options)
370 if content_encoding == "gzip":
371 # Override compression based on Content-Encoding header
372 compression = {"method": "gzip"}
--> 373 reader = BytesIO(req.read())
374 return IOArgs(
375 filepath_or_buffer=reader,
376 encoding=encoding,
(...)
379 mode=fsspec_mode,
380 )
382 if is_fsspec_url(filepath_or_buffer):
File ~/opt/anaconda3/lib/python3.9/http/client.py:476, in HTTPResponse.read(self, amt)
474 else:
475 try:
--> 476 s = self._safe_read(self.length)
477 except IncompleteRead:
478 self._close_conn()
File ~/opt/anaconda3/lib/python3.9/http/client.py:626, in HTTPResponse._safe_read(self, amt)
624 s = []
625 while amt > 0:
--> 626 chunk = self.fp.read(min(amt, MAXAMOUNT))
627 if not chunk:
628 raise IncompleteRead(b''.join(s), amt)
File ~/opt/anaconda3/lib/python3.9/socket.py:704, in SocketIO.readinto(self, b)
702 while True:
703 try:
--> 704 return self._sock.recv_into(b)
705 except timeout:
706 self._timeout_occurred = True
File ~/opt/anaconda3/lib/python3.9/ssl.py:1275, in SSLSocket.recv_into(self, buffer, nbytes, flags)
1271 if flags != 0:
1272 raise ValueError(
1273 "non-zero flags not allowed in calls to recv_into() on %s" %
1274 self.__class__)
-> 1275 return self.read(nbytes, buffer)
1276 else:
1277 return super().recv_into(buffer, nbytes, flags)
File ~/opt/anaconda3/lib/python3.9/ssl.py:1133, in SSLSocket.read(self, len, buffer)
1131 try:
1132 if buffer is not None:
-> 1133 return self._sslobj.read(len, buffer)
1134 else:
1135 return self._sslobj.read(len)
KeyboardInterrupt:
Correlation and covariance#
Create a plot to show the relationship between mean temp (Tmean) and rainfall
# your code here
<AxesSubplot:xlabel='Tmean', ylabel='Rainfall_mm'>
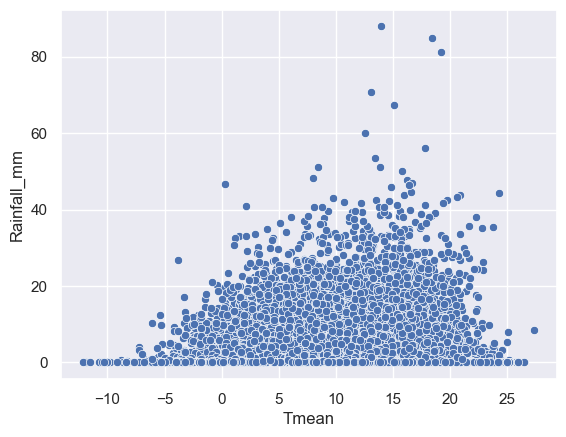
If I want to measure the correlation between Tmean and rainfall, which method should I use?
Using the appropriate method, obtain the full correlation matrix for the weather dataframe
# your code here
| YYYY | MM | DD | Tmax | Tmin | Tmean | Trange | Rainfall_mm | |
|---|---|---|---|---|---|---|---|---|
| YYYY | 1.000000 | -0.003398 | -0.000058 | 0.063688 | 0.083421 | 0.074960 | -0.000478 | 0.055859 |
| MM | -0.003398 | 1.000000 | 0.010523 | 0.180221 | 0.237769 | 0.213777 | -0.016633 | 0.025164 |
| DD | -0.000058 | 0.010523 | 1.000000 | 0.002354 | 0.003191 | 0.002587 | -0.002329 | -0.001199 |
| Tmax | 0.063688 | 0.180221 | 0.002354 | 1.000000 | 0.843880 | 0.967582 | 0.573153 | -0.079592 |
| Tmin | 0.083421 | 0.237769 | 0.003191 | 0.843880 | 1.000000 | 0.950769 | 0.075645 | 0.061870 |
| Tmean | 0.074960 | 0.213777 | 0.002587 | 0.967582 | 0.950769 | 1.000000 | 0.362483 | -0.019287 |
| Trange | -0.000478 | -0.016633 | -0.002329 | 0.573153 | 0.075645 | 0.362483 | 1.000000 | -0.234269 |
| Rainfall_mm | 0.055859 | 0.025164 | -0.001199 | -0.079592 | 0.061870 | -0.019287 | -0.234269 | 1.000000 |
… and just the correlation between Tmean and rainfall
# your code here
-0.019287092574398337
Obtain the covariance between Tmin and Tmax
# your code here
28.59261194330108