
2.6. Data cleaning#
As we have seen, outliers can distort the values of statistics such as the mean and standard deviation
In real datasets, outliers are common, arising from one of the following:
- Real but unusual values (eg many basketball players are outliers in terms of height)
- Noise in a data recording system (eg in brain imaging data, noise signals from head movement are much larger than the real brain activity we are trying to record)
- Data entry error (human types the wrong number)
Identifying and removing outliers and bad data points is a crucial step in the process of preparing our data for analysis, sometimes called data wrangling
Set up Python libraries#
As usual, run the code cell below to import the relevant Python libraries
# Set-up Python libraries - you need to run this but you don't need to change it
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas
import seaborn as sns
sns.set_theme()
Removing an outlier#
In some cases, we can identify that an outlier datapoint should not be in our dataset, and remove it.
Let’s try an example:
Import the data#
Let’s import a dataframe with size information on a random sample of cars
cars = pandas.read_csv('https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook/main/data/cars_outlier1.csv')
display(cars)
| length | height | width | type | |
|---|---|---|---|---|
| 0 | 3.9187 | 1.5320 | 1.8030 | car |
| 1 | 4.6486 | 1.5936 | 1.6463 | car |
| 2 | 3.5785 | 1.5447 | 1.7140 | car |
| 3 | 3.5563 | 1.5549 | 1.7331 | car |
| 4 | 4.0321 | 1.5069 | 1.7320 | car |
| ... | ... | ... | ... | ... |
| 978 | 5.0897 | 1.8396 | 1.8356 | car |
| 979 | 4.0224 | 1.5860 | 1.7862 | car |
| 980 | 3.4771 | 1.5340 | 1.7418 | car |
| 981 | 5.2096 | 1.6396 | 1.8229 | car |
| 982 | 3.7549 | 1.5096 | 1.8274 | car |
983 rows × 4 columns
Get descriptives#
We can get the descriptive statistics using the decribe() method in pandas
cars.describe()
| length | height | width | |
|---|---|---|---|
| count | 983.000000 | 983.000000 | 983.000000 |
| mean | 4.219838 | 1.586132 | 1.793355 |
| std | 0.708656 | 0.131954 | 0.056570 |
| min | 3.110900 | 1.430400 | 1.624100 |
| 25% | 3.816750 | 1.540050 | 1.760250 |
| 50% | 4.121600 | 1.574600 | 1.790400 |
| 75% | 4.520250 | 1.612350 | 1.821000 |
| max | 15.361000 | 4.201700 | 2.499800 |
Hm, the maximum value for car length looks very high.
Let’s plot the data (don’t worry about the plotting code, there is a session on this later)
sns.histplot(cars['length'])
<Axes: xlabel='length', ylabel='Count'>
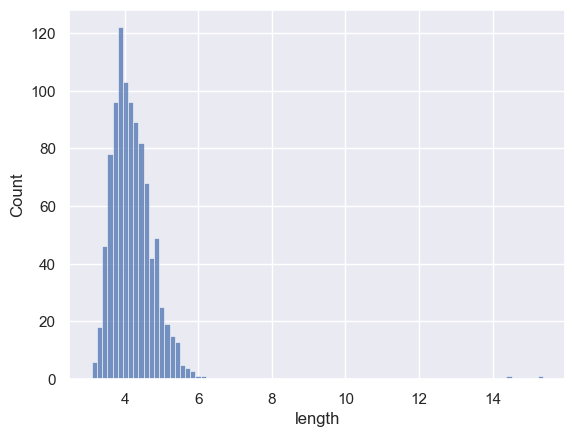
There must be a cars of length up to 15.36m (the max length in the descriptives table) but we can’t see them in the plot - although we can see the x axis is stretched out to accommodate them.
Let’s zoom in a bit:
plt.subplot(1,2,1)
sns.histplot(cars['length'])
plt.subplot(1,2,2)
sns.histplot(cars['length'])
plt.ylim((0,10))
plt.subplots_adjust(wspace = 0.5)
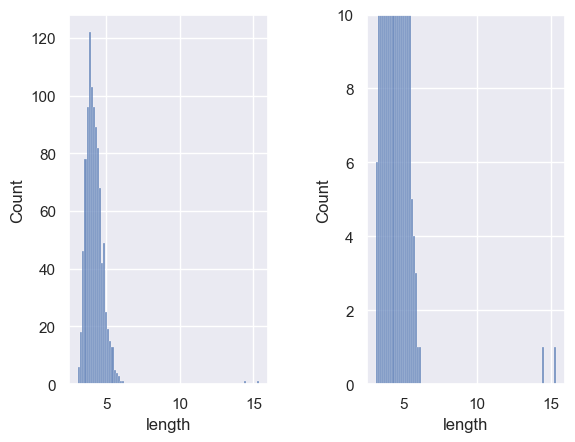
Hm, a couple of outliers.
Let’s check it in the dataframe by pulling out any cars longer than 8m:
cars[cars['length']>8]
| length | height | width | type | |
|---|---|---|---|---|
| 100 | 15.361 | 4.1914 | 2.4998 | truck |
| 101 | 14.508 | 4.2017 | 2.4890 | truck |
ahh, the value of type for the two vehicles that exceed 8m is ‘truck’.
Let’s check what other types we have:
cars['type'].value_counts()
type
car 981
truck 2
Name: count, dtype: int64
Hm, 981 cars and 2 trucks. I think the trucks were included by mistake. Let’s drop them:
cars_clean = cars.drop([100,101]) # 100 is the row index of the truck - you can see it above
cars_clean['type'].value_counts() # check if we still have any trucks in the sample
type
car 981
Name: count, dtype: int64
We got the row indices for the trucks from the cell above where we pulled out rows with length >8m and inspected it.
if you were working with lots of files, it could be useful to cut out the middle man and find the row index using code:
ix = cars.index[cars['type']=='truck'] # find the row index for the truck and save it as 'ix'
cars_clean = cars.drop(ix)
cars_clean['type'].value_counts() # check if we still have any trucks in the sample
type
car 981
Name: count, dtype: int64
NaN an outlier value#
Sometimes, we don’t want to remove an entire entry.
Say for example there is a data entry error for one of the vehicle heights. We might not be that interested in vehicle height, and wish to retain other data on this vehicle.
Then we can replace just the offending value with the value NaN
NaN stands for Not a Number and is code across many programming languages for a missing value that should be ignored.
Let’s try an example
Import the data#
Let’s import a dataframe with size information on a random sample of cars
cars = # your code here to read the file 'https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook/main/data/cars_outlier2.csv'
display(cars)
Cell In[10], line 1
cars = # your code here to read the file 'https://raw.githubusercontent.com/jillxoreilly/StatsCourseBook/main/data/cars_outlier2.csv'
^
SyntaxError: invalid syntax
Get descriptives#
We can get the descriptive statistics using the decribe() method in pandas
# your code here to get the descriptives - check above for an example!
It looks like there are some very high cars in the sample, but the maximum length and width are as expected.
Let’s have a look at the rows of the dataframe containing the very high cars
# your code here to display the rows of the dataframe with car height greater than 8m
# check above for an example
| length | height | width | type |
|---|
Hm, these height values appear to be about 10x the mean height
Maybe a data entry error (the decimal point is in the wrong place)
We can replace the values with a NaN
cars_clean = cars # make a copy of the dataframe to work on
cars_clean.loc[[100,101],['height']]=np.nan
# or cut out the middle man and find the offending row numbers using code
#cars.loc[(cars['height']>8),['height']]=np.nan
# let's view the edited dataframe
display(cars_clean[98:105])
| length | height | width | type | |
|---|---|---|---|---|
| 98 | 4.3451 | 1.6417 | 1.8773 | car |
| 99 | 4.4613 | 1.6514 | 1.7431 | car |
| 100 | 15.3610 | NaN | 2.4998 | truck |
| 101 | 14.5080 | NaN | 2.4890 | truck |
| 102 | 3.9694 | 1.5171 | 1.7158 | car |
| 103 | 4.2810 | 1.5981 | 1.7840 | car |
| 104 | 3.4394 | 1.5124 | 1.7424 | car |
We can see that the mean and max height should now have gone back to reasonable values, as Python just ignores the NaNs when calculating the descriptive statistics:
cars_clean.describe()
| length | height | width | |
|---|---|---|---|
| count | 983.000000 | 981.000000 | 983.000000 |
| mean | 4.219838 | 1.580810 | 1.793355 |
| std | 0.708656 | 0.059263 | 0.056570 |
| min | 3.110900 | 1.430400 | 1.624100 |
| 25% | 3.816750 | 1.540000 | 1.760250 |
| 50% | 4.121600 | 1.574500 | 1.790400 |
| 75% | 4.520250 | 1.611900 | 1.821000 |
| max | 15.361000 | 1.899300 | 2.499800 |
Find NaNs#
If you download a dataset, it can be useful to check which rows have missing values.
You can do this using the method isna, which returns a True for NaN values and False elsewhere.
For example we can check the section of the dataframe where we replaced some values with NaNs
cars_clean[98:105].isna()
| length | height | width | type | |
|---|---|---|---|---|
| 98 | False | False | False | False |
| 99 | False | False | False | False |
| 100 | False | True | False | False |
| 101 | False | True | False | False |
| 102 | False | False | False | False |
| 103 | False | False | False | False |
| 104 | False | False | False | False |
If you want to find the rows in which ‘height’ is NaN, you can use isna() to give indices like this:
cars_clean[cars_clean['height'].isna()]
| length | height | width | type | |
|---|---|---|---|---|
| 100 | 15.361 | NaN | 2.4998 | truck |
| 101 | 14.508 | NaN | 2.4890 | truck |
Delete or NaN?#
When should you delete the entire row and when should you replace a missing value with a NaN?
In general, it is better to replace bad or missing values with a NaN
I think there are three main considerations:
Partial data records are valuable#
If you have many data values for each record or row in your dataframe (in this case, records correspond to individual cars, but they could be patients for example), you may not wish ot junk all the data just because some variables are incomplete or have bad values.
For example, say we run a study which involves a hospital visit for a battery of tests (blood pressure, thyroid function, levels of vitamin B12…) and the lab looses a batch of samples for the B12 analysis. The remaining data on the patients may still be useful - maybe we didn’t even care that much about vitamin B12.
In this case, it is better to put a missing value for B12 in the affected patients and retain the rest of their data as normal.
Deleting data could be misleaading#
Say one of the measures in our patient study is a follow-up questionairre and only 60% of patients complete this.
If we simply delete all the patients who didn’t complete the follow-up from our database, we will have a biased sample (an no-one will ever know!)
For this reason it is good practice to retain incomplete data records, with Nans as appropriate, so another researcher can see the full picture.
Some errors really are errors#
However, if a record is clearly an error (completely empty) or a duplicate (two identical files for the same NHS number), it would be appropriate to delete it